Train Stable Diffusion Locally

In diesem Recipie schauen wir uns an, wie wir ein Stable Diffusion Modell lokal auf unserem PC trainieren können, um einen bestimmten Stil zu erzeugen. Was ist ein LoRA? Welche Daten braucht es? Was sind die Vor- und Nachteile eines lokalen Trainings? Wie lange dauert es ein LoRA zu trainieren?
Upcoming Event:
Was ist ein LORA?
LoRAs (Low-Rank Adaptations) sind kleinere Modelle , die Du mit bestehenden Stable Diffusion Modellen kombinieren kannst. Sie erlauben es ein Bestehendes Modell «Fine zu tunen». So kannst du neue Konzepte wie Styles, Subjekte und Objekte (je nach LoRA) in deinen generierten Bildern hinzufügen. Die Methode zum training spezieller Stile / Konzepte die wir hier nutzen ist hier ziemlich ausführlich beschrieben: Dreambooth.
Diese neuen Konzepte fallen ganz grob unter 2 Kategorien:
- Stile
- z.B. Wasserfarbe, VHS Glitches, Comic Styles, Kartoffelstock, Glas ect.,
- Subjekte / Objekte
- Prominente Personen / Charaktere
- z.B. LiamGallagher, Rhianna / Lara Croft, Sauron ect.
Um ein LoRA zu aktivieren kannst du unter dem Tab LoRA ein entsprechendes LoRA aktivieren wichtig hierbei ist, dass das LoRA auch mit dem Basismodell kompatibel ist.
Beispiele für die Anwendung von LoRA`s findest du hier: Stable Diffusion – webUI
Was für Daten brauche ich um ein eigenes LoRA zu trainieren?
Du brauchst dafür ein Dataset von ca. 10-30 Bildern. Dies können Bilder eines bestimmten Stils, eines Objekts oder z.B. des Gesichts einer Person (Selfies) sein.
Was sind vor- und nachteile eines Lokalen trainings?
Vorteile
Ein lokales Training ermöglicht es dir, deine Daten lokal auf unserem Computer zu trainieren. Das bedeutet, dass du deine persönlichen Daten nicht auf einen Server irgendwo auf der Welt hochladen musst, um sie zu trainieren. Alles passiert hier im MediaDock auf unserem Computer. Wenn du zum Beispiel ein Modell deines Gesichts trainieren willst, musst du dafür nicht deine biometrischen Daten in Form von Selfies auf einem Server in den USA trainieren. Oder wenn du einen Test machen willst, wie dein Illustrationsstil auf verschiedenen Bildern aussieht, brauchst du auch hier deine Daten nicht ins Netz zu hängen.
Nachteile
Ein Nachteil kann sein, dass das Training auf unserer Maschine etwas länger dauert. Auf unserem lokalen Rechner dauert es zwischen 30 Minuten und mehreren Stunden, bis ein Training abgeschlossen ist.
Ein qualitativ hochwertiges LoRA kann auf unserem lokalen Rechner schwieriger zu erreichen sein als auf einer bereits sehr gut kalibrierten Online-Version.
Wie lange braucht es ein LORA zu trainieren?
Auf unserem Rechner haben wir für ein Training zwischen 30min – mehrere Stunden. Dies hängt von der Grösse deines Datensatzes und den eingestellten Parametern ab.
Training mit Kohya_ss
Du hast einen Datensatz von 10-30 Bildern und willst ein Training versuchen? Lets Go!
starte Kohya_ss
Öffne das Terminal und benutze folgende Kommandozeilen nach einander: (ohne das $-Zeichen)
$ cd '/home/medo/Documents/Applications/dreambooth/kohya_ss' $ ./gui.sh --listen 127.0.0.1 --server_port 7870 --inbrowser
Dataset Ethik
Bei Datensätzen für KI trainings solltest du beachten, dass es gewisse ethische Probleme geben kann.
Fürs Training unbedenklich sind Bilder:
- die du selber gemacht hast, dir selber gehören, deine Autorschaft tragen
- die im Besitz von Personen die dir klar und deutlich ihre Zustimmung gegeben haben
- die unter Creative Commons (CC0) veröffentlicht wurden
- deren Copyright schon länger abgelaufen ist oder die nicht unters Urheberrecht fallen
Dataset Vorbereitung
BLIP Captioning
Als erstes versehen wir die Bilder mit einem maschinell generierten Bildbeschrieb. Hierzu müssen wir alle Bilder in unserem Datansatz einem BLIP- Captioning unterziehen. Dieses findest du unter:
Utilities > Captioning > BLIP-Captioning.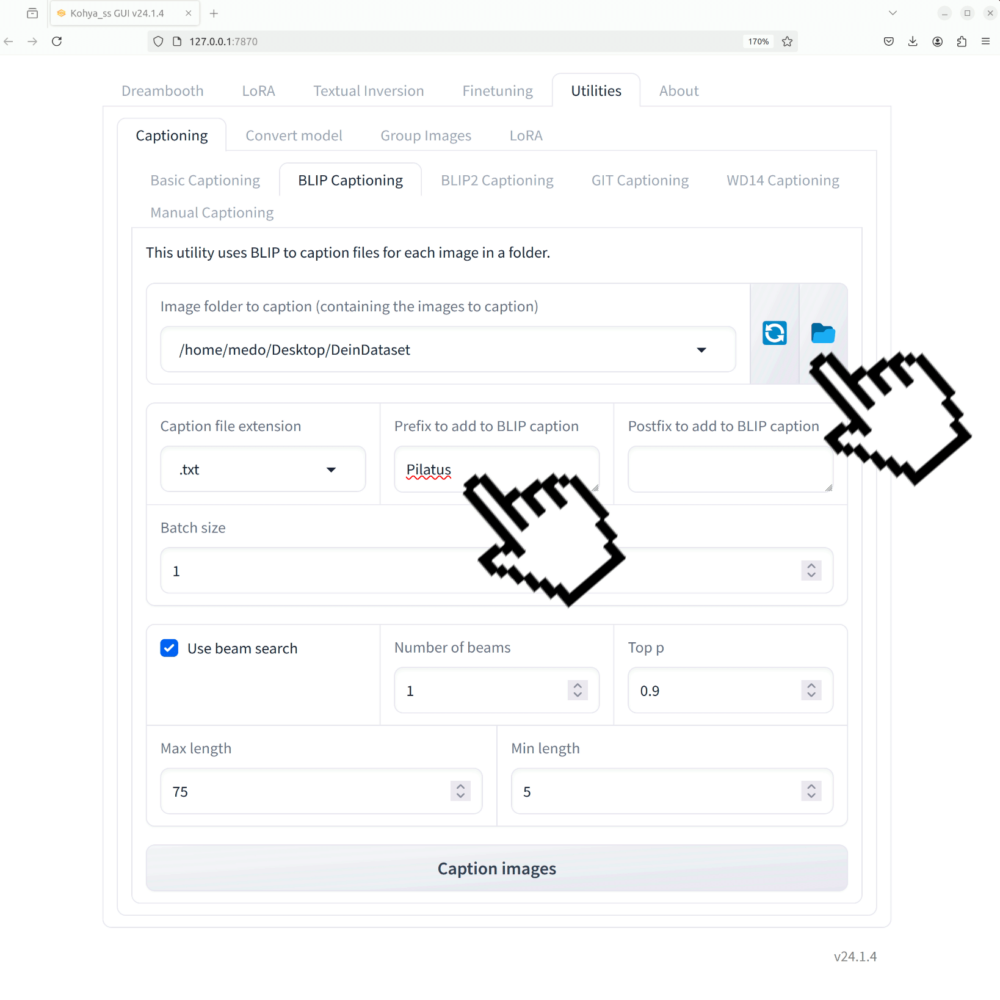
- Du gibst an, wo dein Bilddatensatz gespeichert ist: in meinem Fall auf dem Desktop im Ordner PilatusDataset.
- schreibst du dein LoRA Triggerwort als Prefix in das dafür vorgesehene Eingabefeld.
ACHTUNG: Dieses Wort wird später verwendet, um dein trainiertes Objekt / deinen trainierten Stil im Prompt zu erwähnen und die LoRA auszulösen. Es kann ein Phantasiewort sein, sollte aber kein allgemein beschreibendes Wort wie Berg sein. Mehr dazu später in der Anleitung.
Wenn diese beiden Bedingungen erfüllt sind, klicke auf Caption Images.
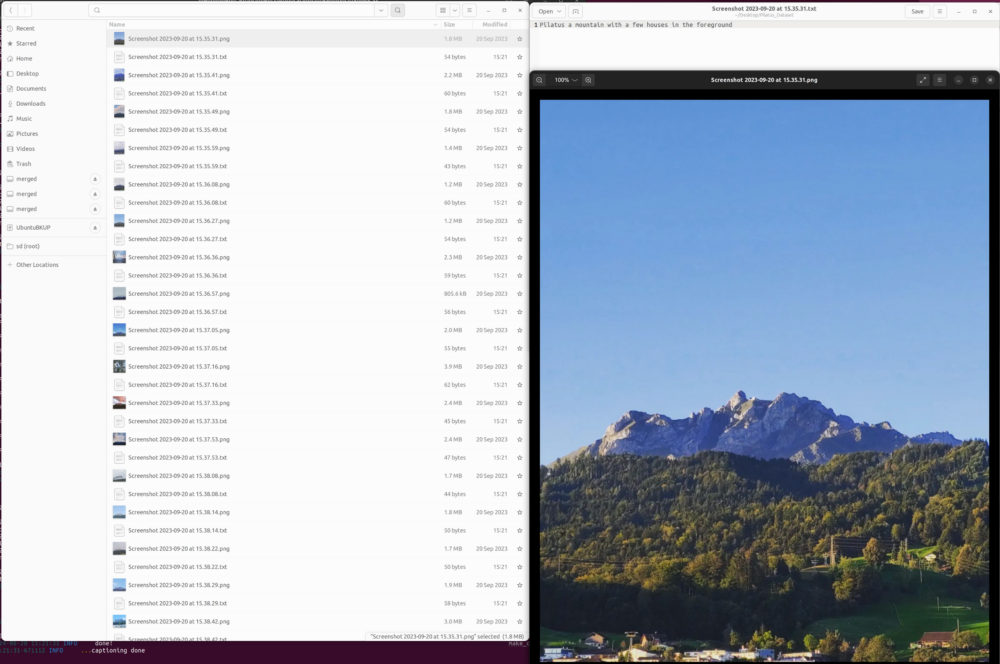
Nach dem Caption Prozess hast du eine Beschreibung für jedes Bild in deinem Dataset Ordner als txt erstellt. Diese Beschreibungen sind für das weitere Training sehr wichtig. Kontrolliere kurz ob die Beschreibungen korrekt sind:
LoRA Training
Wir wechseln zu folgendem Tab:
LoRA > Training > Dataset Preparation
- Als erstes wollen wir sicherstellen, dass unser Dataset Pfad festgelegt ist.
- Als Instance Prompt geben wir unser «Triggerwort» ein in unserem Fall war das Pilatus.
- Als class Prompt geben wir die allgemeine Klasse dieses Objekts ein in unserem Fall wär das mountain
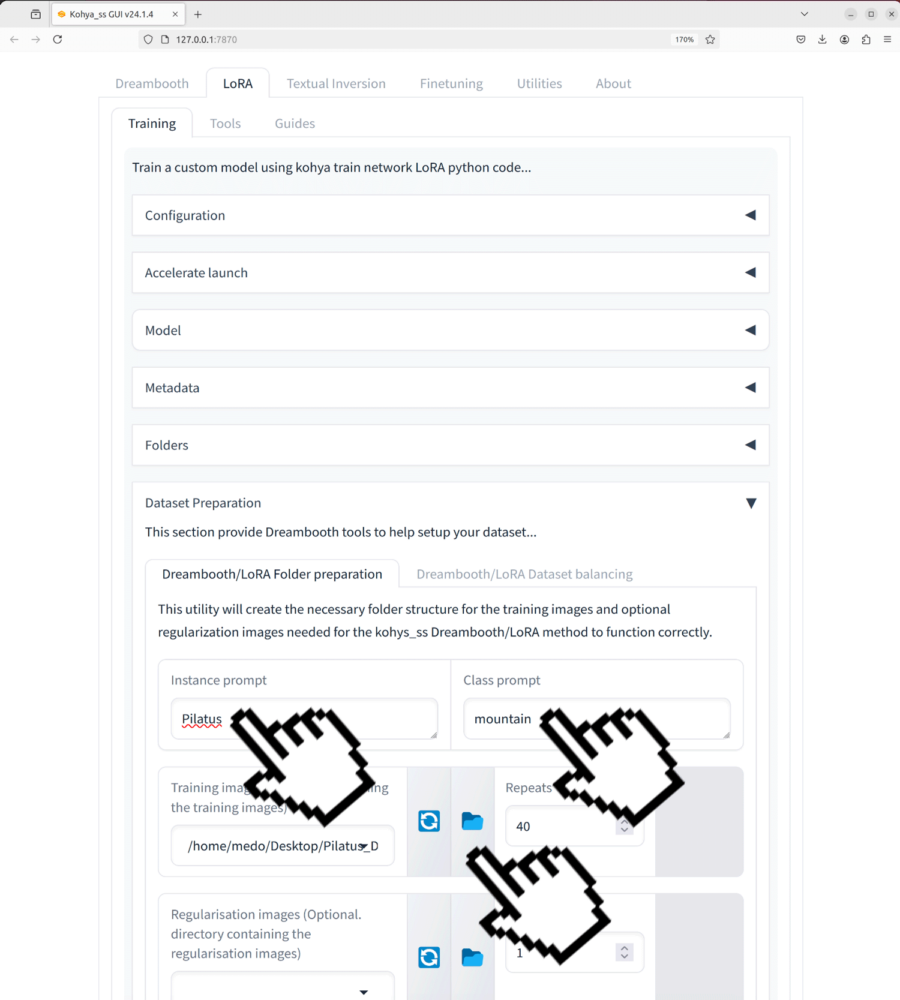
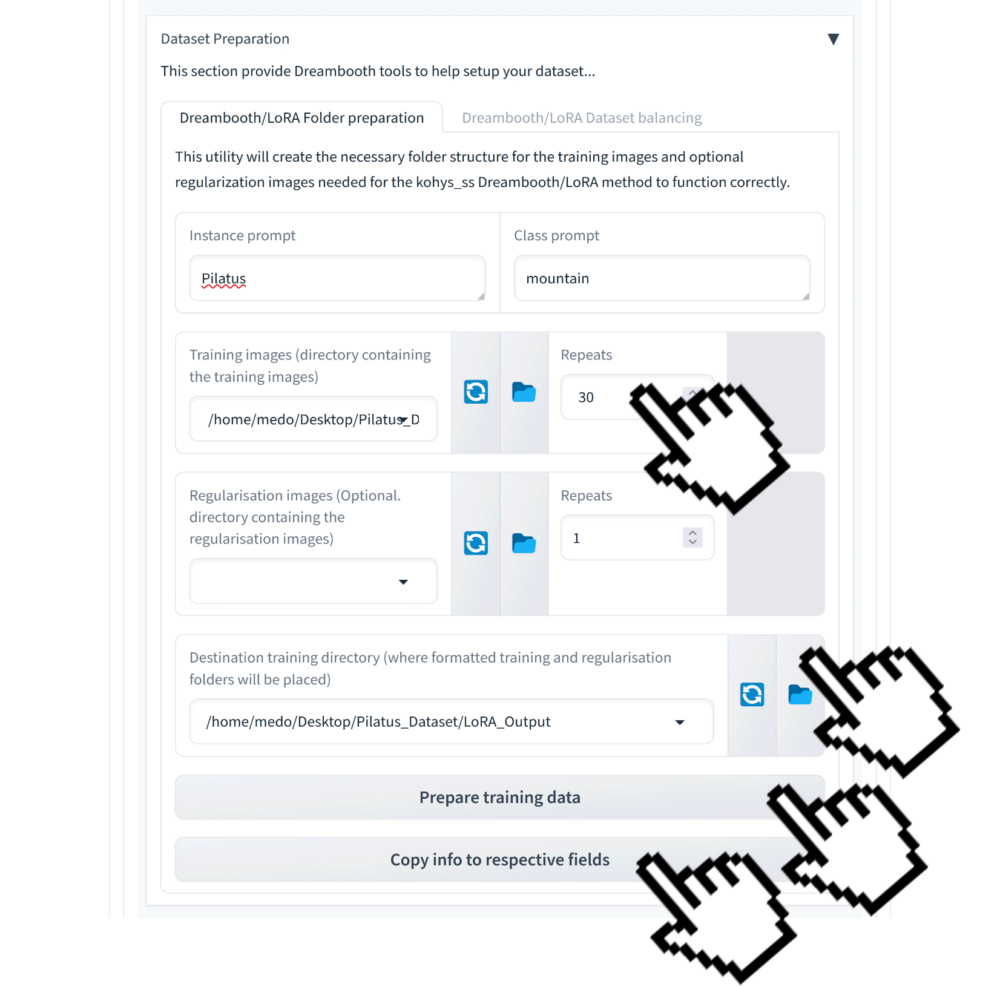
Nun wollen wir die Repeats etwas herunterschrauben Default ist 40 wir nehmen hier 30 evt. können auch schon 20 zu vernünftigen Resultaten führen.
Wir bestimmen den Output Ordner, in unserem Fall ist das ein Ordner mit dem Namen Output_Lora. Und dann klicken wir auf Prepare training data und Copy info to respective fields.
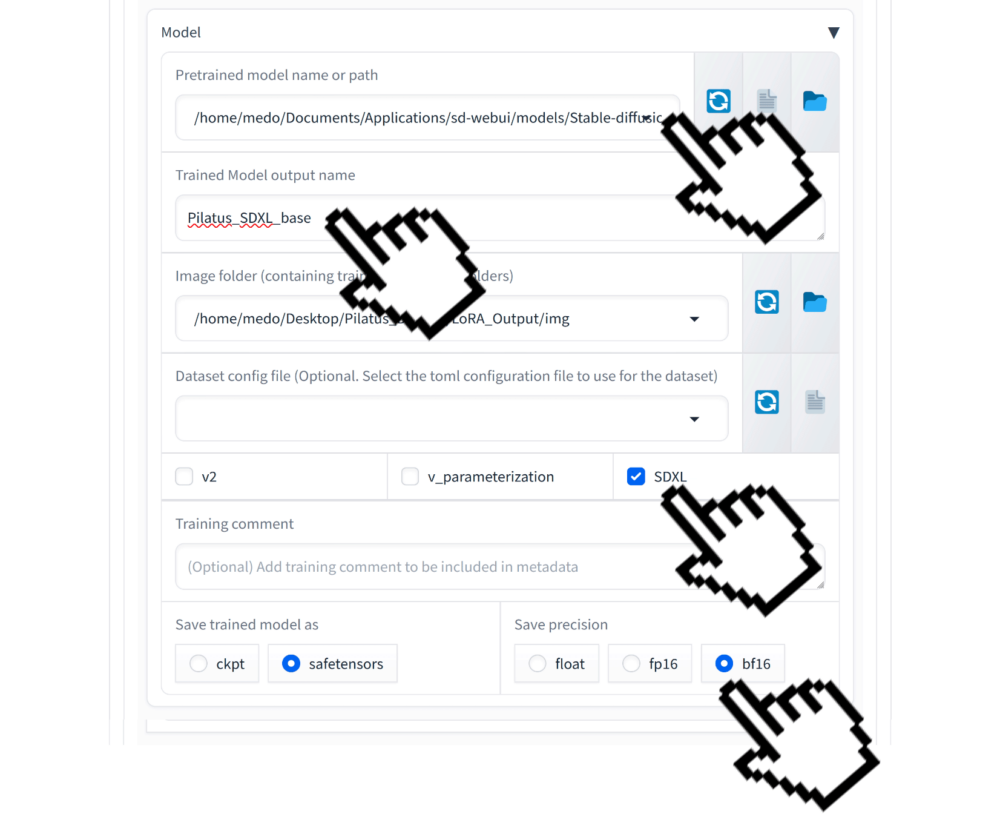
Model Tab
Im Model Tab legen wir fest, welcher Pfad zu unserem BaseModell führt. Wir nutzen ein Stable Diffusion XL Model als Base und während des Lora Trainings „schrumpfen” wir dieses Modell auf die für LoRA relevanten Daten.
Der Pfad auf unserem Rechner geben wir am einfachsten manuell ein:
/home/medo/Documents/Applications/sd-webui/models/Stable-diffusion/sd_xl_base_1.0_0.9vae.safetensors
Unser Name für das Trainierte Modell wählen wir gleich unterhalb ich benenne meine Trainierten Modell mit dem einem Hinweis auf das Basismodell welches für das Training benutzt habe: Pilatus_XL_Base
Da wir ein Stable Diffusion XL Modell trainieren setze ich das Häckchen bei SDXL.
Und da wir eine ziemlich eine starke Grafikkarte (NVIDIA RTX 5000 Ada Generation) haben setzen wir die Präzision auf bf16
Parameters
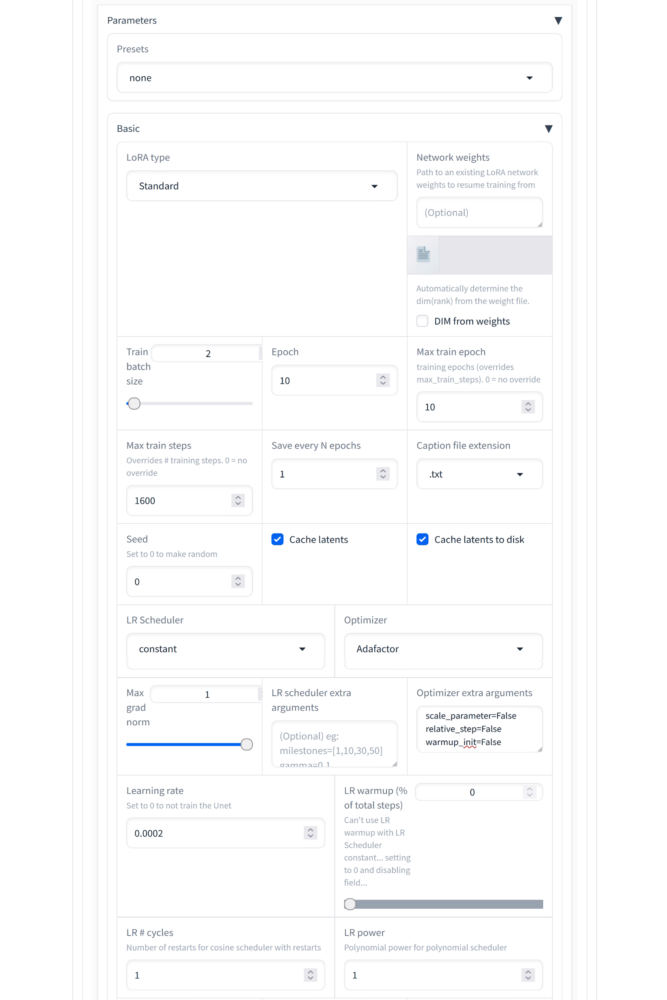
Als Nächstes öffnen wir den Parameters Tab. Hier wollen wir folgende Einstellungen vornehmen:
- Train batch size: 2
- Epoch: 10
- Max train epochs: 10
- Cache latents: checked
- Cache latents to disk: checked
- LR Sheduler: constant
- Optimizer: Adafactor
- Optimizer extra arguments: scale_parameter=False relative_step=False warmup_init=False
- Learning Rate: 0.0002
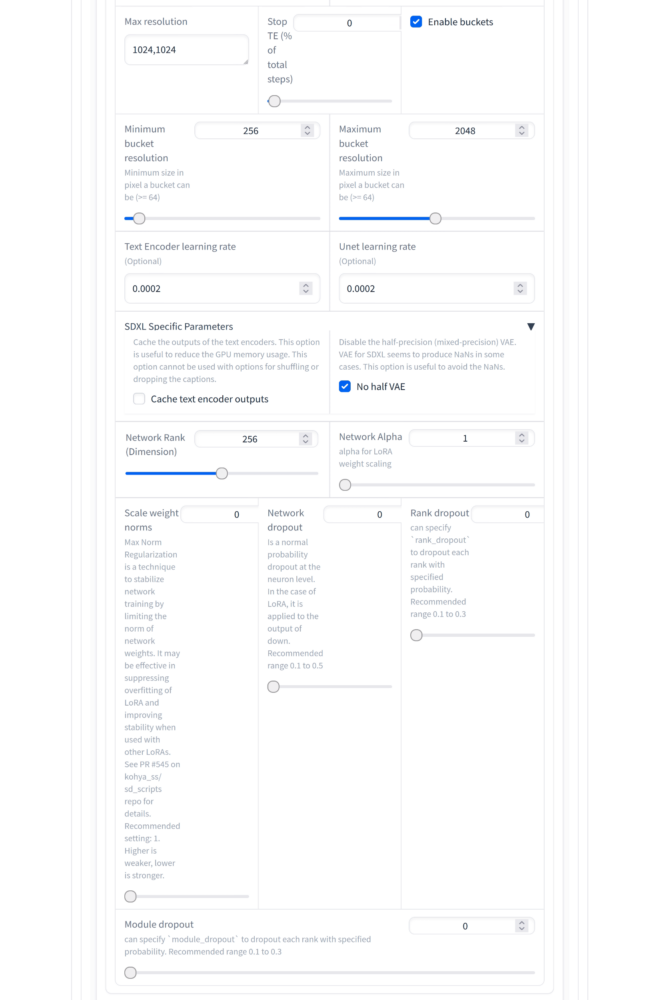
- Max resolution: 1024, 1024
- Text Encoder learning rate: 0.0002 (or the same as Learning Rate)
- Unet learning rate: 0.0002
- No half VAE: checked
- Network Rank (Dimension): 256
Parameters Advanced
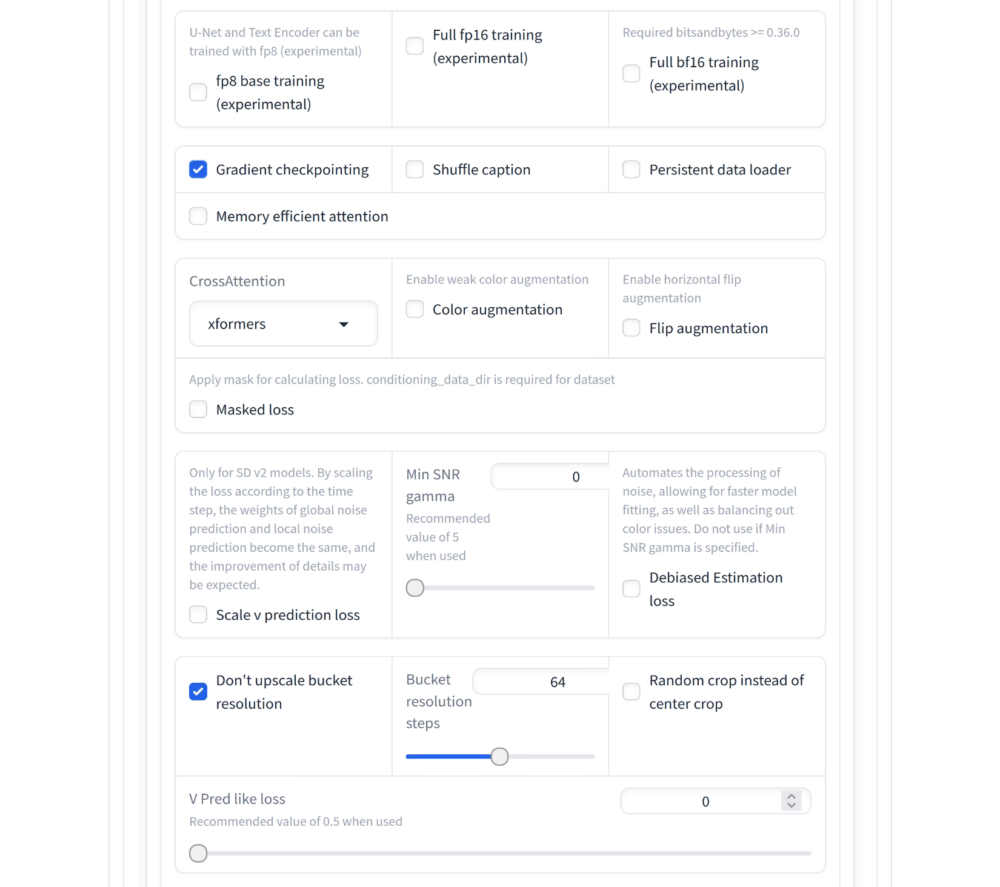
Im Advanced Tab stellst du nun noch sicher, dass die beiden Checkmarks gesetzt sind
- Gradient checkpointing: checked
- Don`t upscale bucket resolution: checked
Final Click: Train Button
Nun darfst du endlich den Train button drücken und dem Fortschritt im Terminal zuschauen:
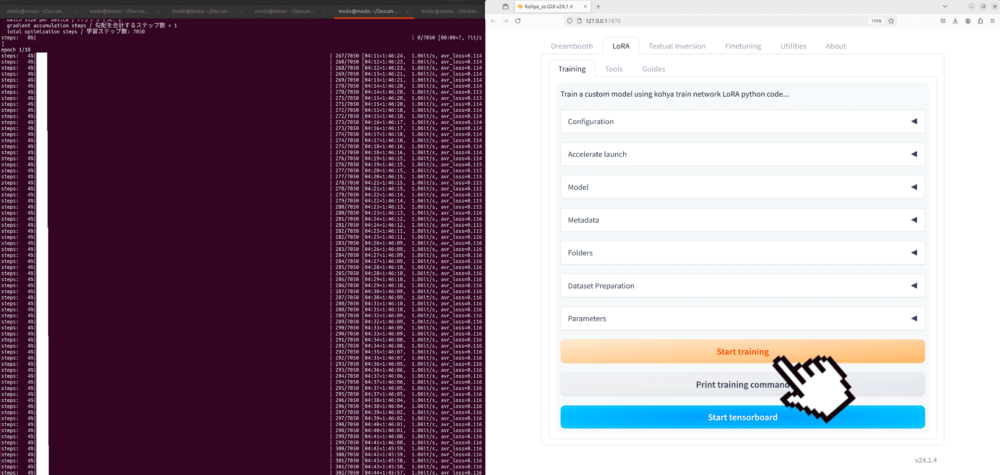
Anwendung des Modells
Nachdem das training abgeschlossen ist, solltest du 10 .safetensor Files in der Grösse von ca. 1,7 GB in dem Output folder haben. diese .safetensor Files kannst du nun in den LoRA Folder der WebUI kopieren:
/Documents/Applications/sd/stable-diffusion-webui/models/Lora
Sobald dies gemacht ist, starte deine Liebste Stable Diffusion Applikation (WebUI oder Fooocus) und setze unter Advanced neben dem BasisModell auch den Refiner ein. Danach kannst du das trainierte LoRA Modell hinzuschalten.
Die Einstellungen die ich für die Verwendung genommen habe sind:
- sd_xl_base_1.0_0.9vae.safetensors
- sd_xl_refiner_1.0_0.9vae.safetensors
- Refinerswitch: ~ 0.5
- Pilatus_SDXL_base-000009.safetensors
- Lora Weight: ~ 0.8
Prompt
Wichtig ist, dass du beim prompt das vorher bestimmte Triggerwort in unserem Fall «Pilatus» einbaust. So wird das LoRA aktiviert:
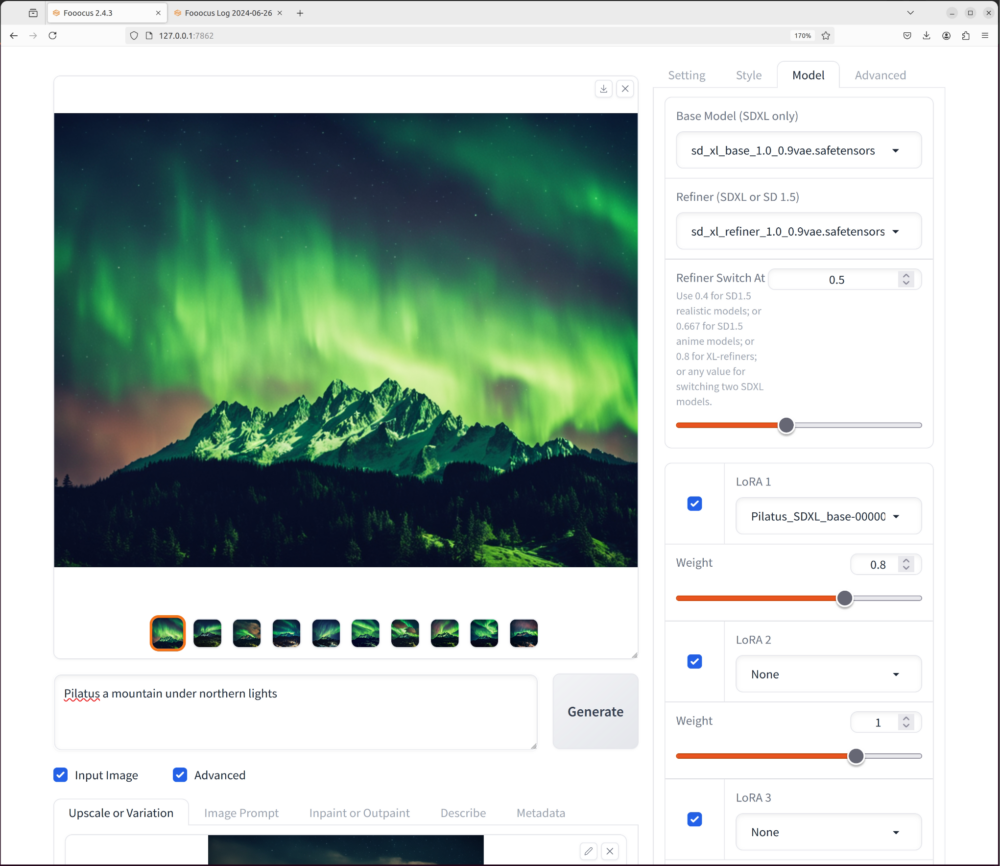 Die Resultate:
Die Resultate:










