Stable Diffusion Fooocus

Stable Diffusion ist ein Text-Bild-Diffusionsmodell, das in der Lage ist, aus beliebigen Texteingaben Bilder in unterschiedlichsten Stilen zu generieren. Wir haben es im MediaDock auf unserem ML Rechner installiert. Hier erklären wir dir, wie du es startest, Modelle auswählst, Stile anpasst und es generell nutzen kannst.
Prolog
Nebst diversen Diffusion Modellen, die sich Online nutzen lassen (Dall-e, Midjourney ect.) lässt sich Stable Diffusion auch Lokal auf einem Rechner im MediaDock nutzen und mit zusätzlichen Steuermöglichkeiten ausstatten. Hier im MediaDock haben wir auf unserem Rechner viele verschiedene Modelle installiert wie auch Benutzeroberflächen installiert.
Diese hier ist im Gegensatz zur WebUI etwas einfacher zu bedienen.
Stable Diffusion Fooocus
Dokumentation
https://github.com/lllyasviel/Fooocus
Start Fooocus
Die Software, die wir hier nutzen um Stable Diffusion simple zugänglich zu machen heisst Fooocus. Um sie zu starten öffnest du das Terminal in Ubuntu und nutzt folgende Kommandozeilen:
$ cd '/home/medo/Documents/Applications/sd/iart-stable_diffusion_docker' $ docker compose up -d fooocus
Diese paar Zeilen starten das Programm Fooocus und es startet im Browser unter folgender IP Adresse: 127.0.0.1:7658
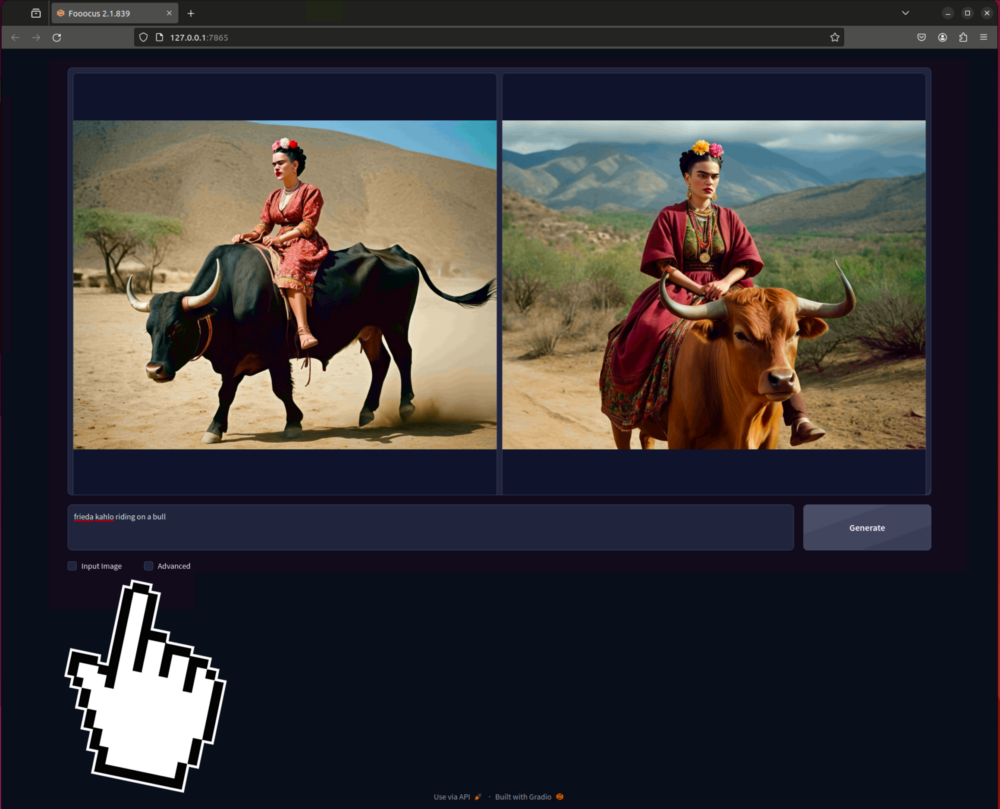
 Nach dem Start des Programms öffnet sich Firefox automatisch unter der lokalen IP adresse und du kannst mit Prompts exakt gleich wie bei der WebUI Bilder generieren: Prompt eingeben und Generate Button klicken.
Nach dem Start des Programms öffnet sich Firefox automatisch unter der lokalen IP adresse und du kannst mit Prompts exakt gleich wie bei der WebUI Bilder generieren: Prompt eingeben und Generate Button klicken.
Advanced Modes
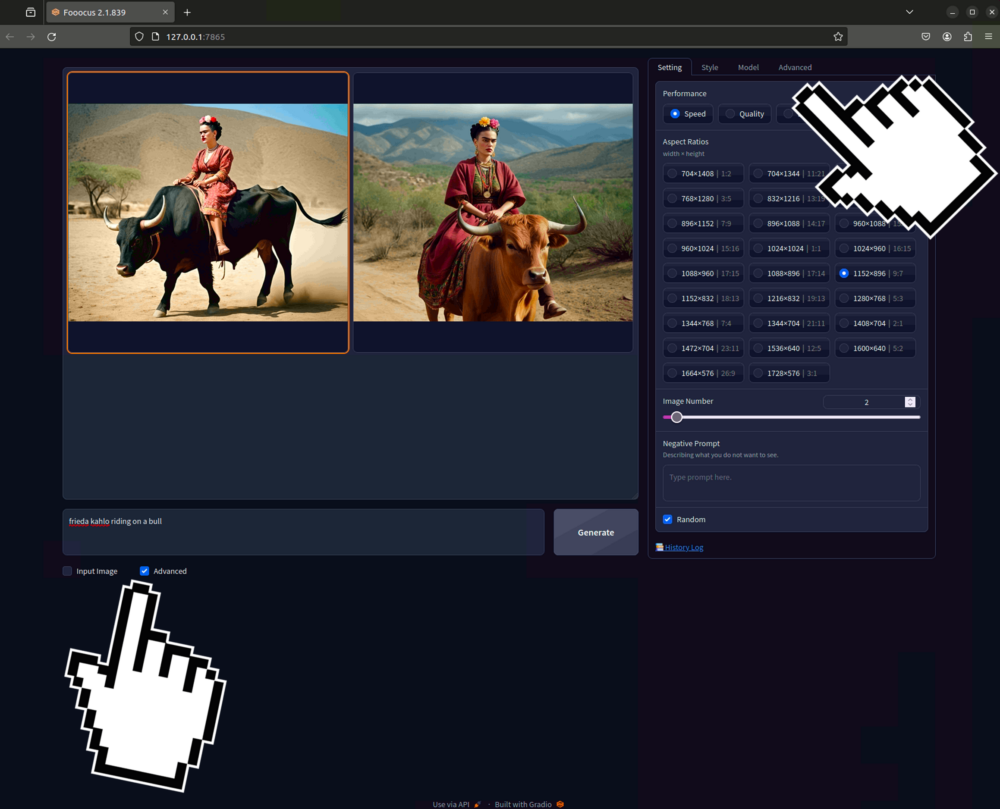
Setzt du die Häckchen bei Advanced oder bei Image Input bekommst du weitere Optionen die du nebst dem Prompt nutzen kannst. Hier schauen wir uns kurz die Advanced Optionen an:
Setting
Hier kannst du als erstes zwischen Qualität und Speed priorisieren und das Seitenverhältnis des Bildes (Länge x Breite in Pixel) bestimmen wie die Anzahl generierter Bilder in einer Inferenz bestimmen. Dies ist gleich wie der Batchcount in der WebUI. Des weiteren lässt sich hier auch einen Negativ Prompt eingeben (was soll nicht in deinem Bild enthalten sein).
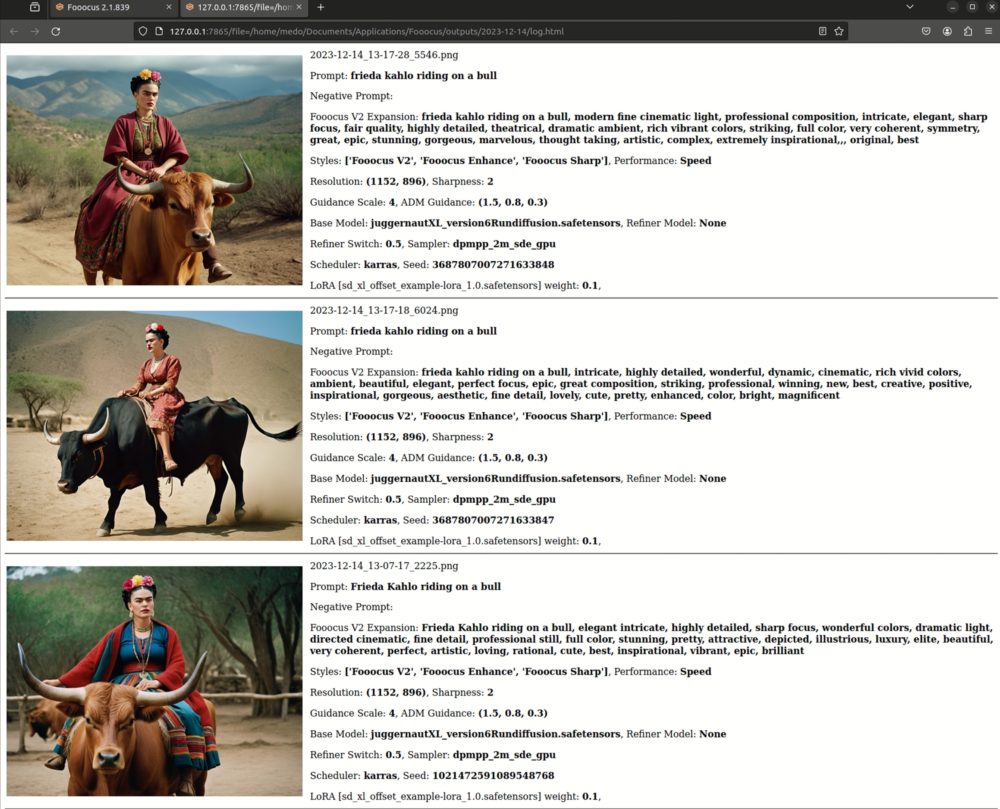
Wenn du ganz unten auf den Link klickst, dann kommst du in die Session History. Das hier hast du den überblick was für einstellungen du gemacht hast um ein entsprechendes Bild zu generieren. Funfact: hier siehst du auch was Fooocus alles zusätzliches zu deinem Prompt hinzudichtet um ein «schönes» Bild zu erhalten.
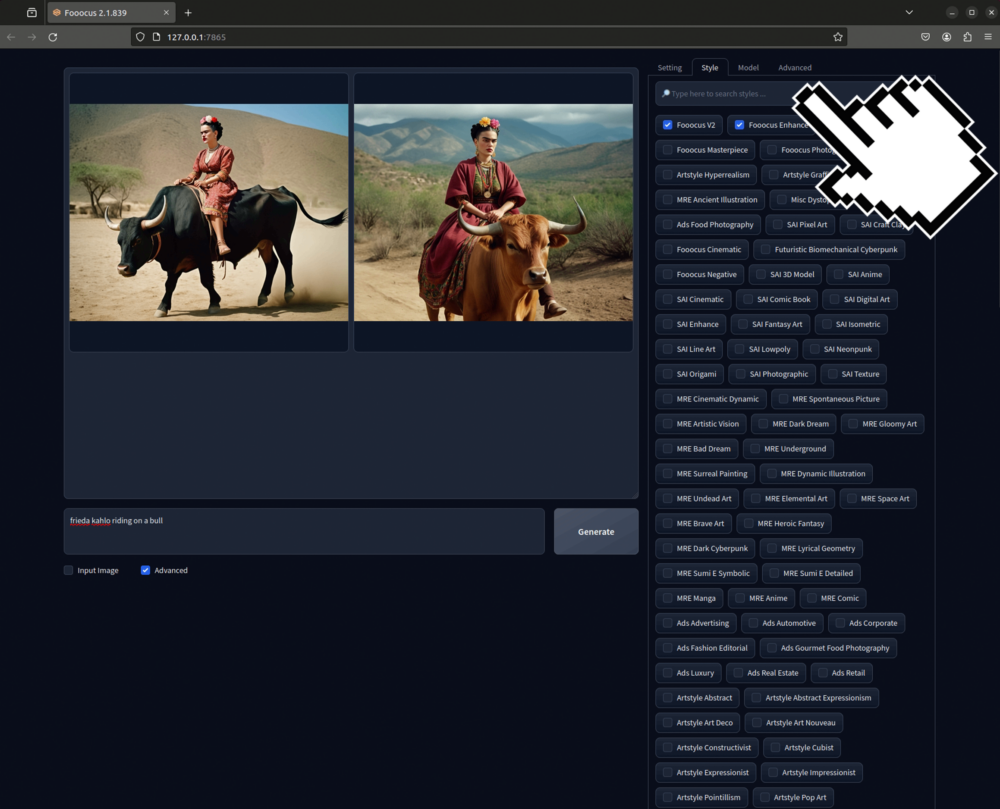
 Style
Style
Unter Syles kannst du diverse Checkmarks setzen die den Style der generierten Bilder beeinflussen. Nicht alle Styles wirken auch automatisch bei jedem Modell. Am besten probierst du einfach aus was bei deinem angewählten Modell einen Effekt hat.
 Model
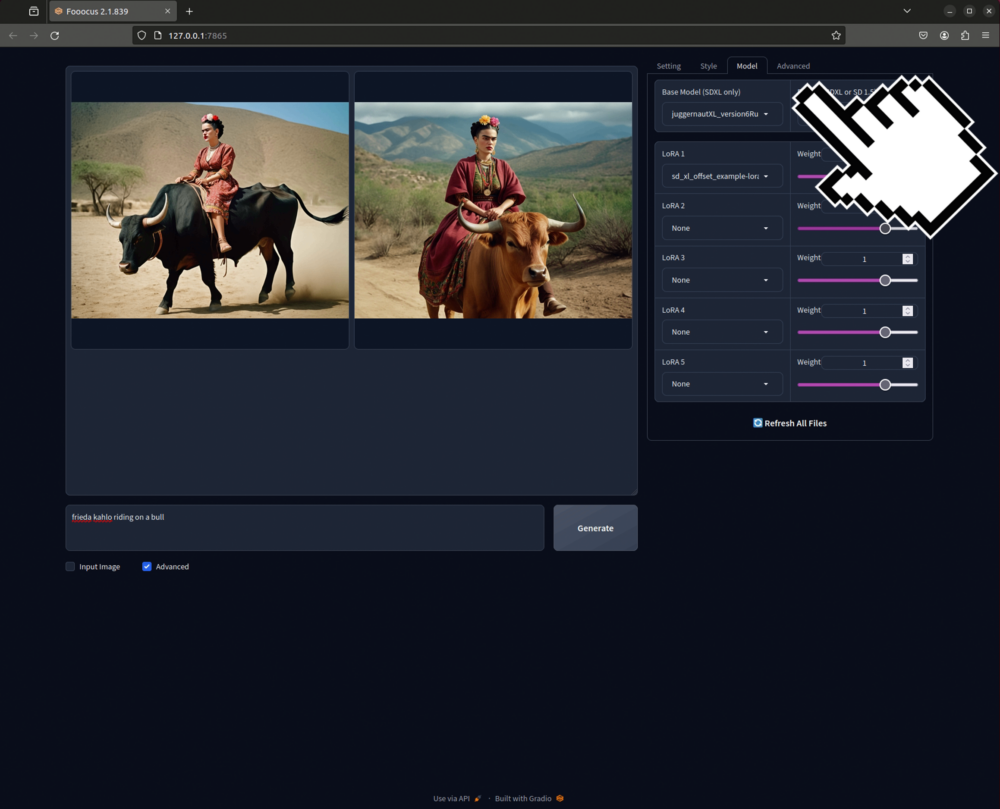
Model
Hier kannst du das Basis Modell bestimmen. Default ist SD XL 1.0 aber es lassen sich auch andere Modelle auswählen / installieren. Wenn dich ein spezifisches Modell interessiert können wir dies für dich installieren.
 Advanced
Advanced
Im Advanced Tab vom Advanced Menü ist es möglich die
- Orientierungsskala (Guidance Scale)
Ein höherer Wert bedeutet, dass der Stil sauberer, lebendiger und künstlerischer ist. - Bild Schärfe (Image Sharpness)
Ein höherer Wert bedeutet, dass Bild und Textur schärfer sind.
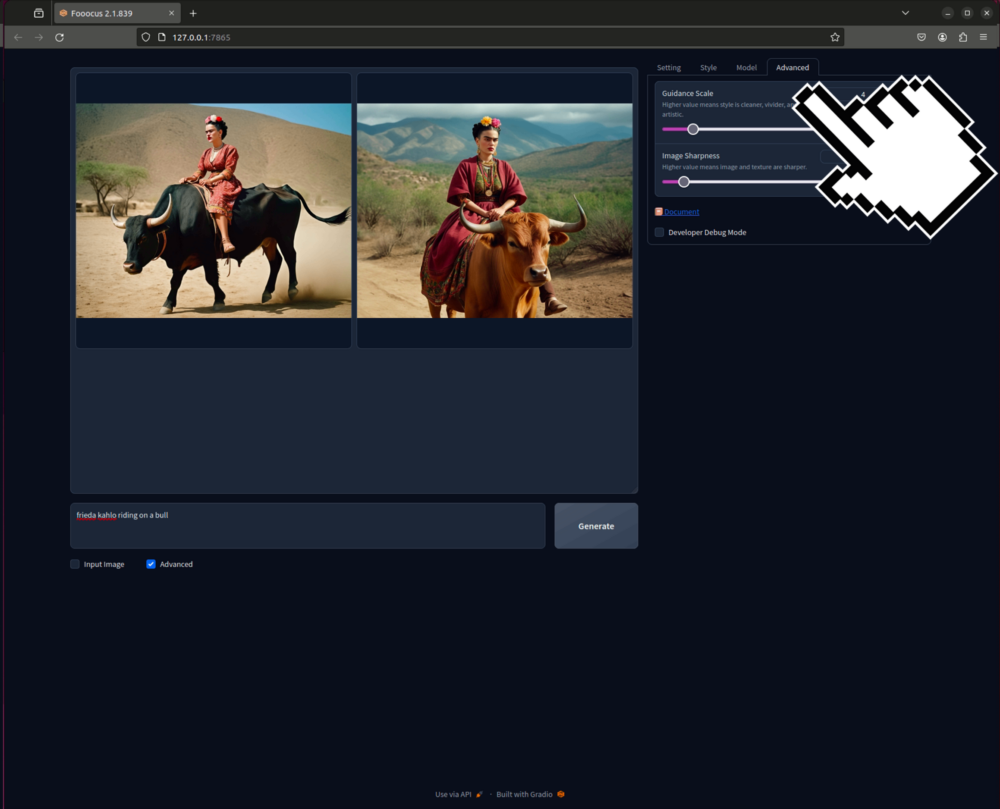
Image Input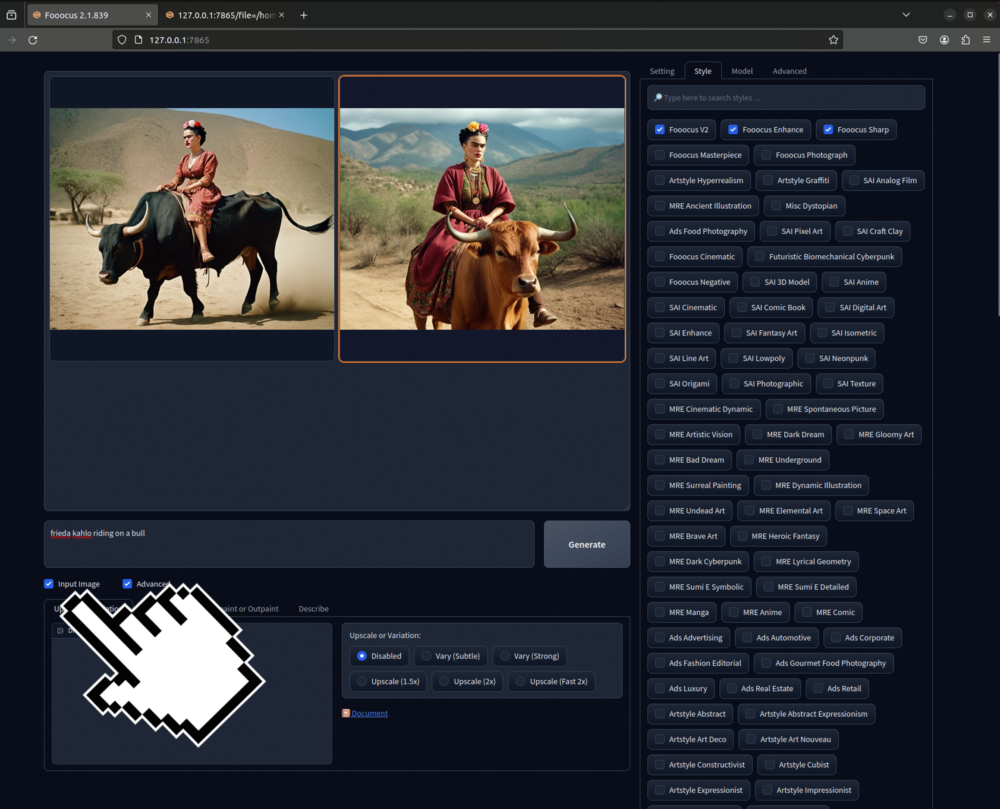
Upscale or Variation
Hier kannst du ein Bild Variieren oder Upscalen. Das heisst, du kannst hier ein Bild mit leichten oder grösseren Variationen Re-Generieren oder es Vergrössern.
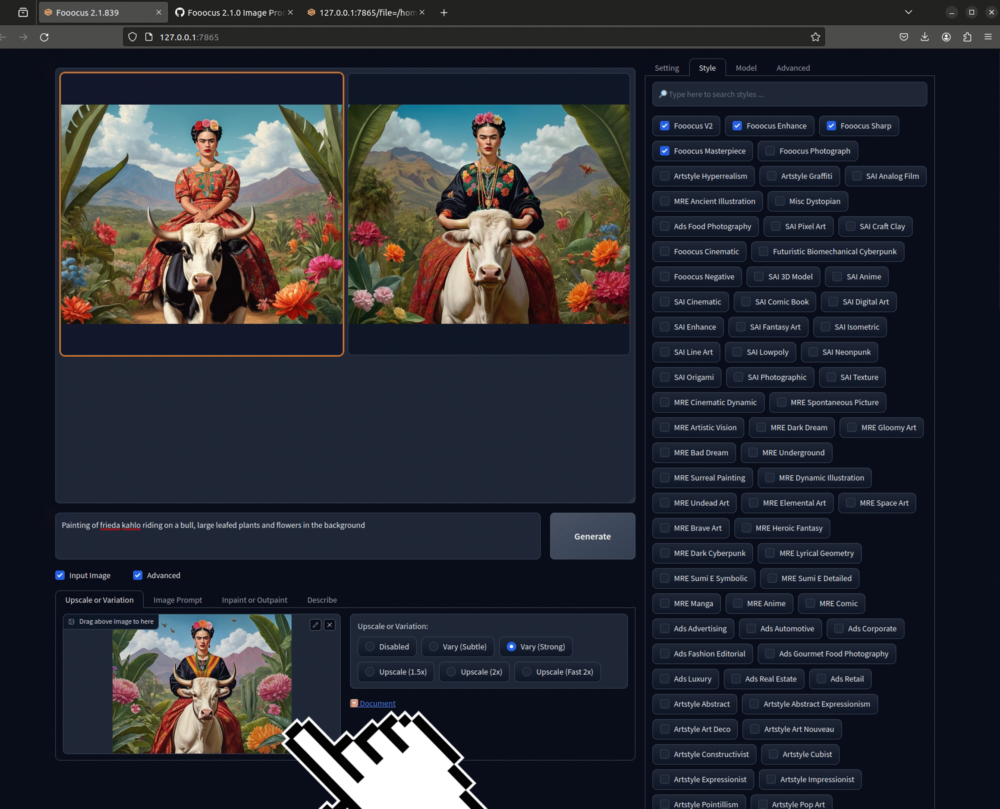 Image Prompt
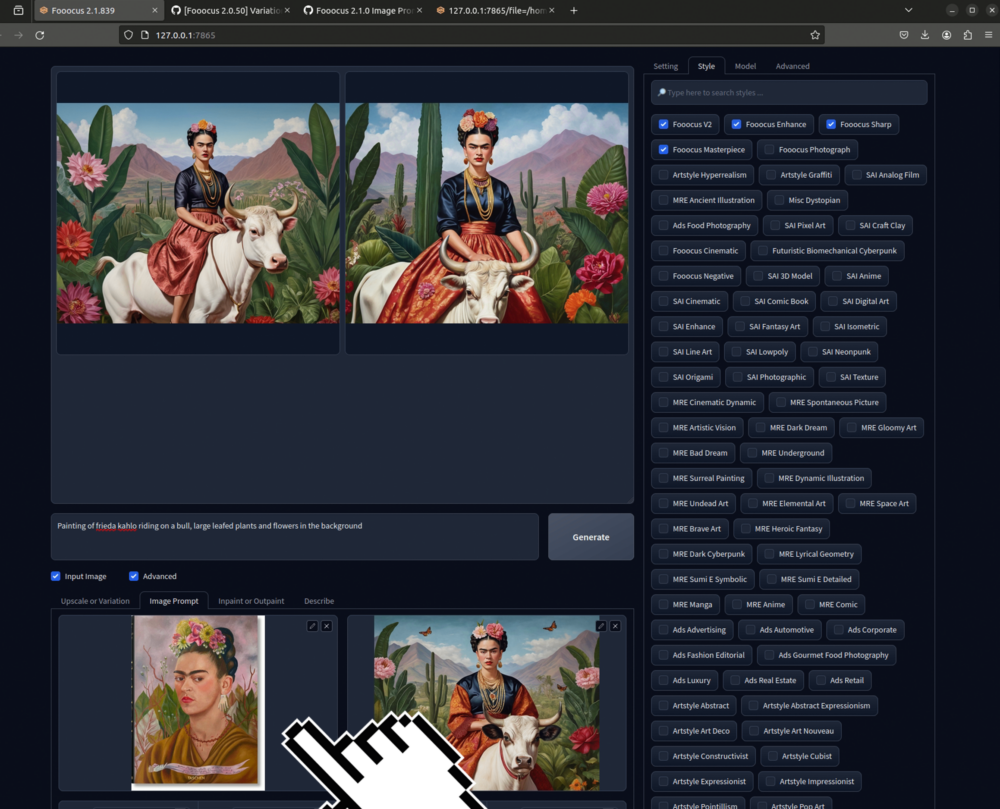
Image Prompt
Hier kannst du verschiedene Input Bilder mit einander «verschmelzen».
Dokumentation zum Image Prompt
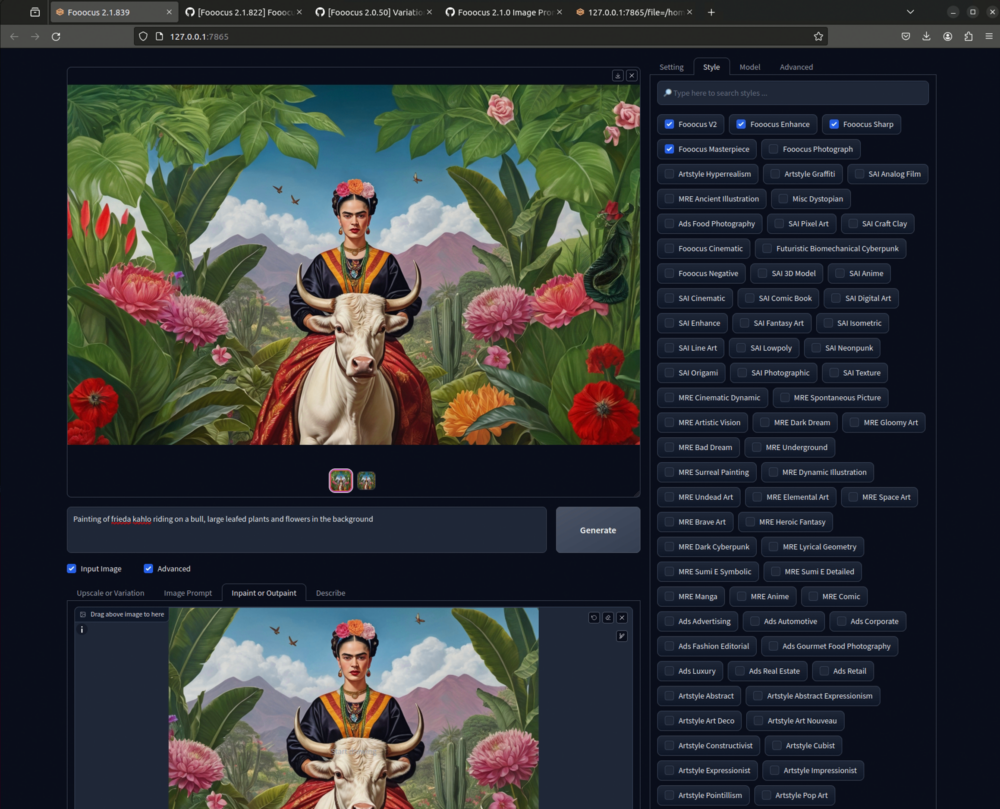
Outpaint
Lässt dich Bilder erweitern und partiell Korrigieren in unserem Beispiel habe ich links, rechts und oben das Bild erweitert.
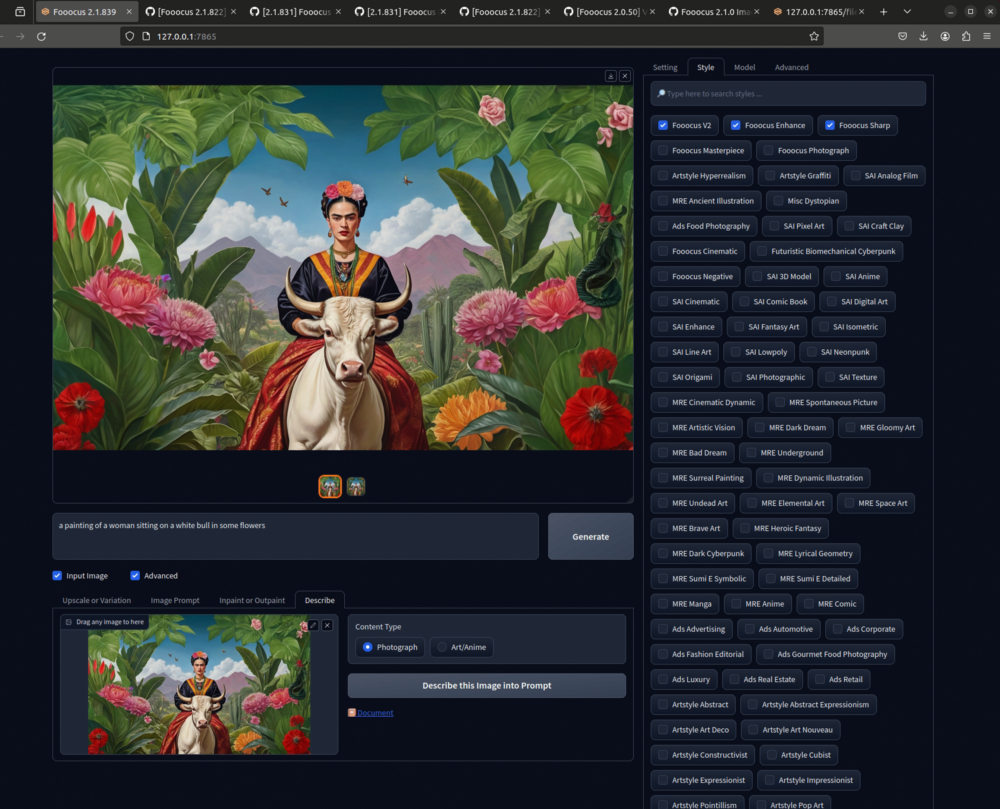
Describe
Hier kannst du Prompt Engineering betreiben: Speise ein Bild ein um zu sehen wie Stable Diffusion das Bild analysiert und welche Prompts du als Startpunkt nehmen kannst in meinem wurde «a painting of a woman sitting on a white bull in some flowers» maschinell herausgelesen.
Daten zum abschliessenden Bild






