Stable Diffusion – webUI

Stable Diffusion ist ein Text-Bild-Diffusionsmodell, das in der Lage ist, aus beliebigen Texteingaben fotorealistische Bilder zu generieren. Wir haben es im MediaDock auf unserem ML Rechner installiert. Hier erklären wir dir, wie du es startest, Modelle auswählst, LoRA (Low-Rank Adaptations) und ControlNet nutzen kannst.
Prolog
Nebst diversen Diffusion Modellen, die sich Online nutzen lassen (Dall-e, Midjourney ect.) lässt sich Stable Diffusion auch Lokal auf einem Rechner im MediaDock nutzen und mit zusätzlichen Steuermöglichkeiten ausstatten. Hier im MediaDock haben wir auf unserem Rechner viele verschiedene Modelle, Controlnet und LoRA’s installiert, um dir beim Generieren von Bildern nebst den Prompts auch noch zusätzliche Kontrolle zu geben.
Stable Diffusion webUI
Dokumentation der webUI
https://profaneservitor.github.io/sdwui-docs/de/
Start webUI
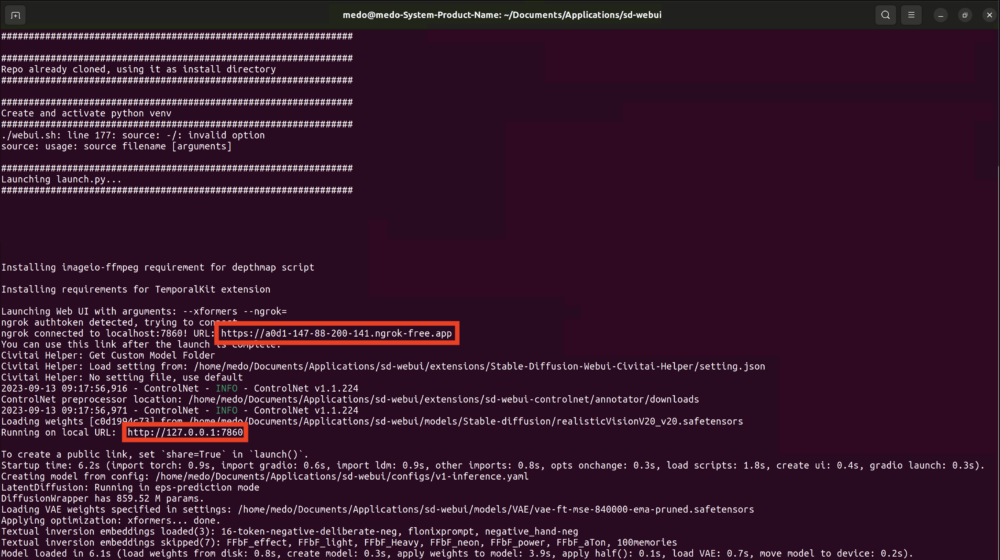
Die Software, die wir nutzen um Stable Diffusion zugänglich zu machen heisst webUI um sie zu starten öffnest du das Terminal in Ubuntu und nutzt folgende Kommandozeilen:
$ cd '/home/medo/Documents/Applications/sd/iart-stable_diffusion_docker' $ docker compose up webui
Diese paar Zeilen starten das Programm webUI und einen Webservice suche in dem Terminal nachfolgenden Links:
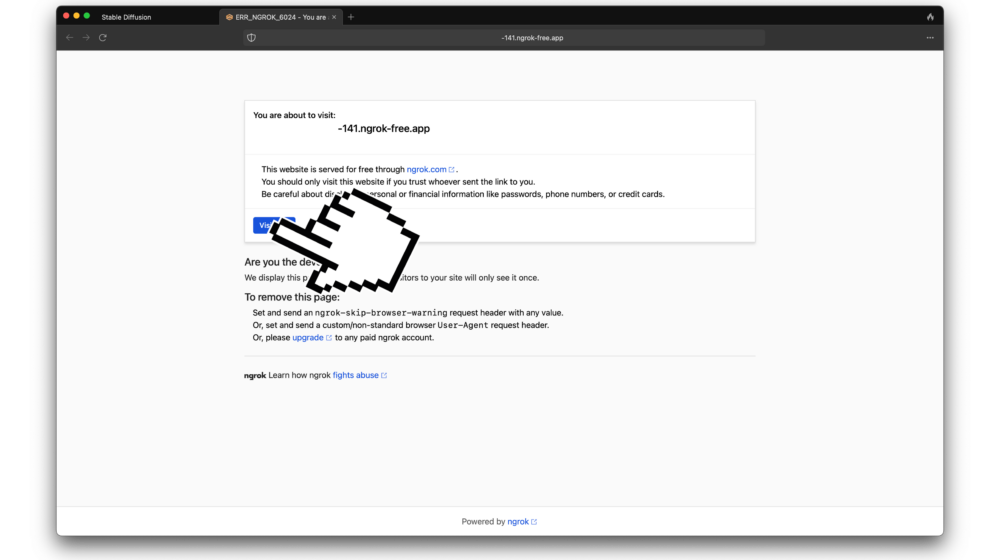
Online Zugriff von deinem Rechner
Falls du von jedem x beliebigen Computer im Internet aus mit dem Tool arbeiten willst, öffne den «ngrok link» in deinem eigenen Browser danach greifst du Remote auf den Machine Learning Rechner zu. Dieser Link wird bei jeder Session neu generiert, versuche es also nicht mit dem Link auf dem Bild (der ist schon längst nicht mehr aktiv). Kopiere den Link aus dem Terminal und nutze ihn auf deinem Computer / Laptop. Klicke «Visit Site» und du bist drin.
Lokal direkt an der Workstation
Falls du lokal direkt an unserem Rechner arbeiten möchtest, kannst du den zweiten Link nehmen und die IP http://127.0.0.1:7860 in einem Browser auf dem Rechner öffnen.
In beiden Fällen öffnet sich die webUI: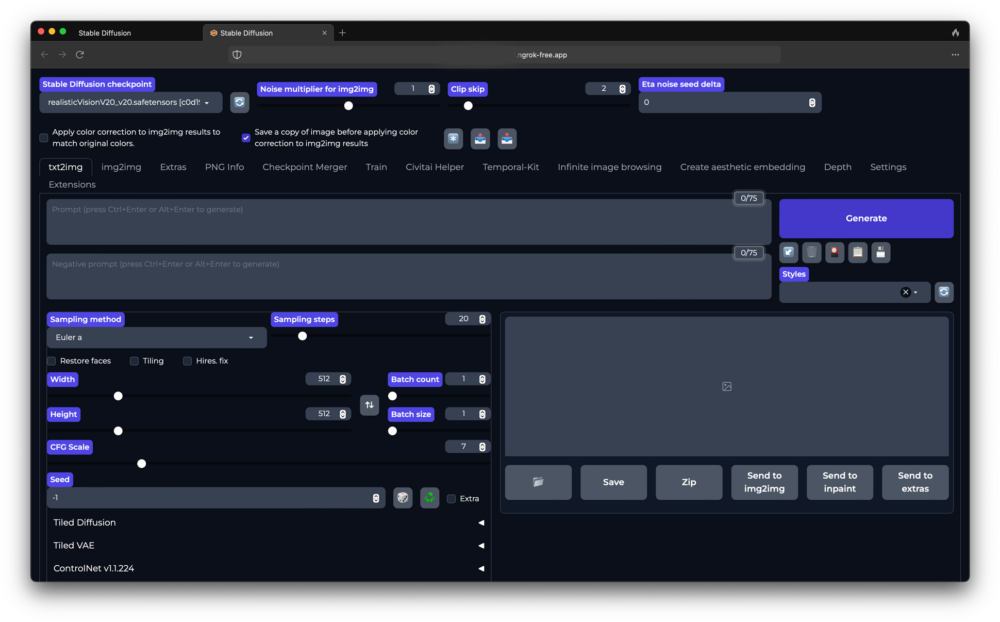
Basic Workflow
Modell Wählen
Das Basis Modell kannst du Links oben im Dropdown Menu oder über den Reiter Checkpoints auswählen. Aktuell sind um die 15 verschiedene «Geschmacksrichtungen» von Stable Diffusion installiert. Nebst den Basismodellen (z.B. SD 1.5; SDXL) sind auch Modelle installiert die z.B. auf Fotorealismus, einer Erscheinung wie analoge Fotografie ausgelegt sind.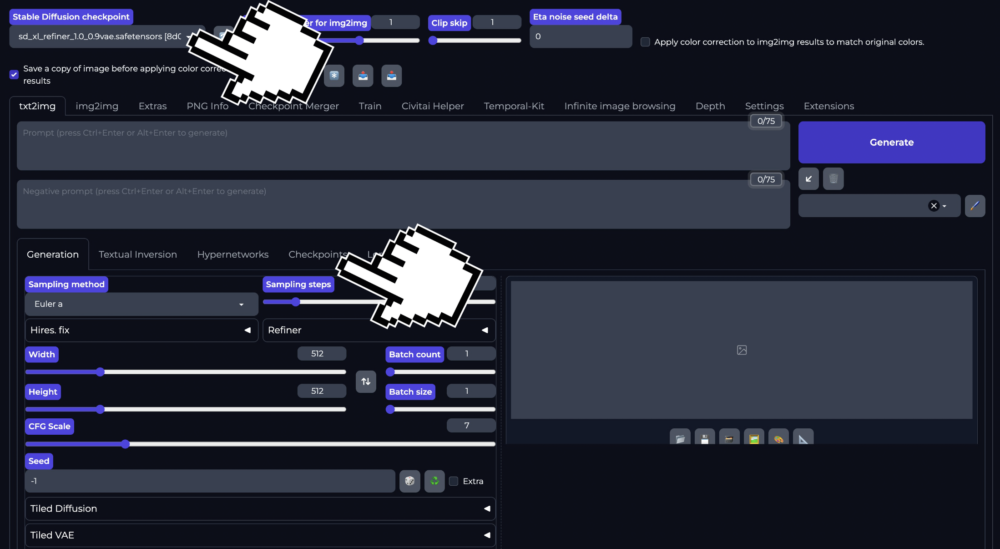
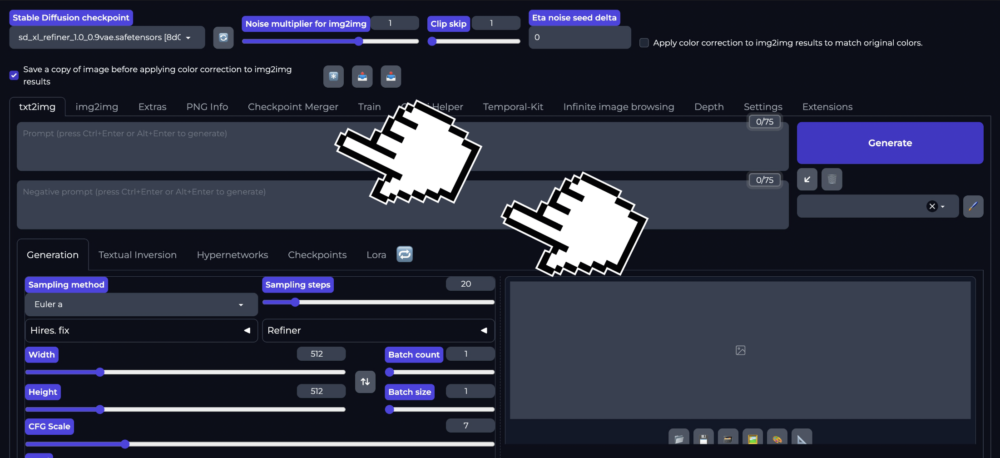
Prompt / Negativprompt eingeben
Ein Prompt wird als Bildbeschrieb eingegeben, um das Bild durch das Stable Diffusion Modell zu generieren. Du kannst auch einen Negativprompt verfassen um gewisse Dinge sicherlich nicht in deinen Bildern zu haben. Prompts können sehr einfach sein in unserem Beispiel nutzen wir «Photo of Karl Marx riding on a Bull» oder sehr elaboriert sein und diverse wichtige Keywords beinhalten:
Wie komplex auch immer dein Prompt ist hier ist die Eingabefläche:
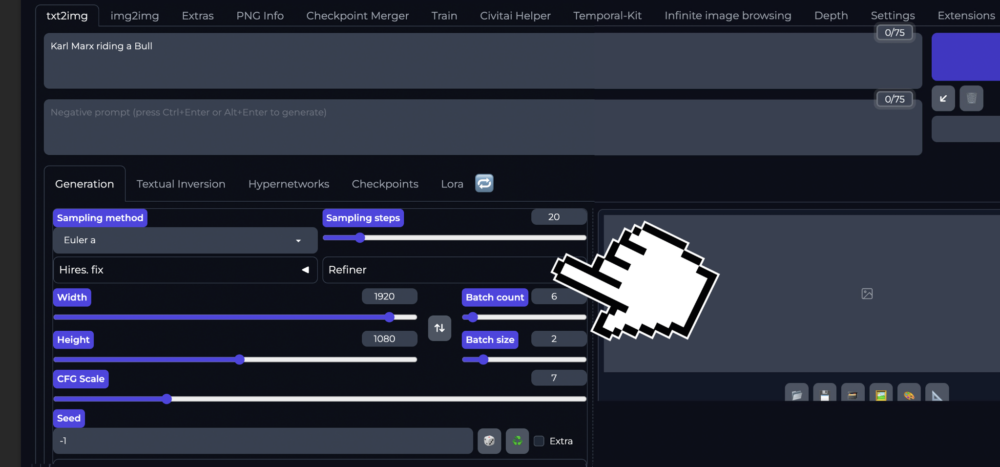
Bildeinstellungen vornehmen
In den Bildeinstellungen können wir nun die Breite und Höhe einstellen und einen Batch count wie eine Batch size Festlegen.
In meinem Beispiel hier produziere ich die Bilder mit folgender Einstellung:
- 2 Serien à 4 Bilder
- 1920 x 1080 Pixel
Kleinere Bilder gehen immer schneller und kosten weniger Energie im Prozess als grosse – bist du also auf der Suche nach einem Bild dann generiere idealerweise kleinere Bilder z.B. 512 x 512 Pixel.
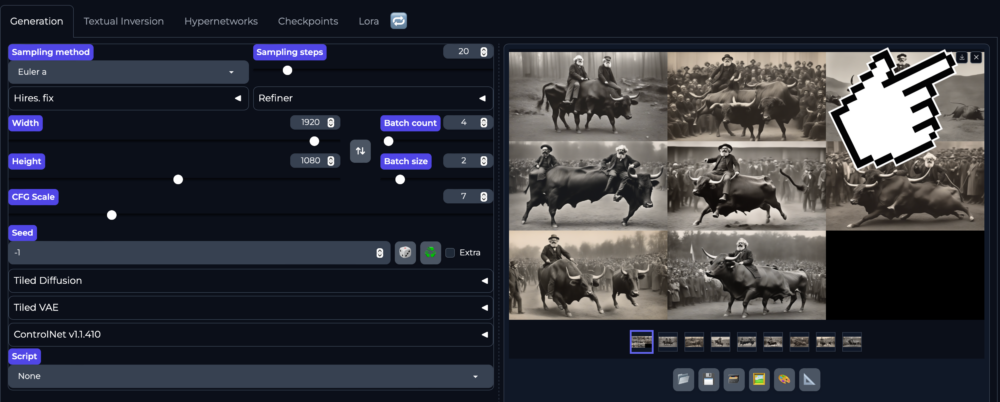
Zwei Batches mit je 4 Bildern sehen als Output folgender Massen aus:

Bilder Speichern oder Downloaden
Den Download eines Bildes auf deinen eigenen Rechner kannst du mit dem Klick auf das Download Symbol rechts oberhalb der Preview auslösen:
Backup
Falls du vergessen hast ein Bild zu speichern oder herunterzuladen, ist das halb so schlimm. Stable Diffusion WebUI speichert alle generierten Bilder nach Datum in folgendem Ordner:
/Documents/Applications/sd-webui/outputs
Mehr Kontrolle über die generierten Bilder
Wenn du mehr Kontrolle über das Bild, z.B Stil oder Komposition erlangen willst, gibt es verschiedene Möglichkeiten dies zu forcieren:
- Prompt Engineering
- Image to Image
- Modelle und LoRA`s: Kontrollmöglichkeit über den im Stil
- Controlnet: Kontrollmöglichkeit über die Komposition
- Kombinationen von Controlnet und LoRa`s
Prompt-Engineering
Es gibt viele Möglichkeiten die generierten Bilder genauer zu gestalten. Viele Modelle wie Dalle, Midjourney, erlauben dir vor allem über Prompt Engineering eine grössere Kontrolle über das generierte Bild zu erlangen. Bei einer kleinen Suche im Netz findest du für diese Modelle schnell Anleitungen, mit denen du dir aneignen kannst, wie ein präziser Prompt auszusehen hat. Selbstverständlich kannst du mit einem auf ein Modell zugeschnittenen Bildbeschrieb deine generierten Bilder stärker steuern.
Ein interessantes Tool, um solche für Maschinen lesbaren Bildbeschriebe zu generieren ist zum Beispiel dieses hier:
https://replicate.com/pharmapsychotic/clip-interrogator
Oder der eingebaute CLIP interrogator in der web-UI.
Image to Image
Wenn du verschiedene Varianten eines Bildes generieren möchtest, kannst du «Image to Image» nutzen. Hier kannst du auf Basis eines Bildes weitere Varianten generieren. In meinem ersten Beispiel habe ich den Prompt gleich gelassen und ein Bild aus meiner vorherigen Serie hochgeladen.
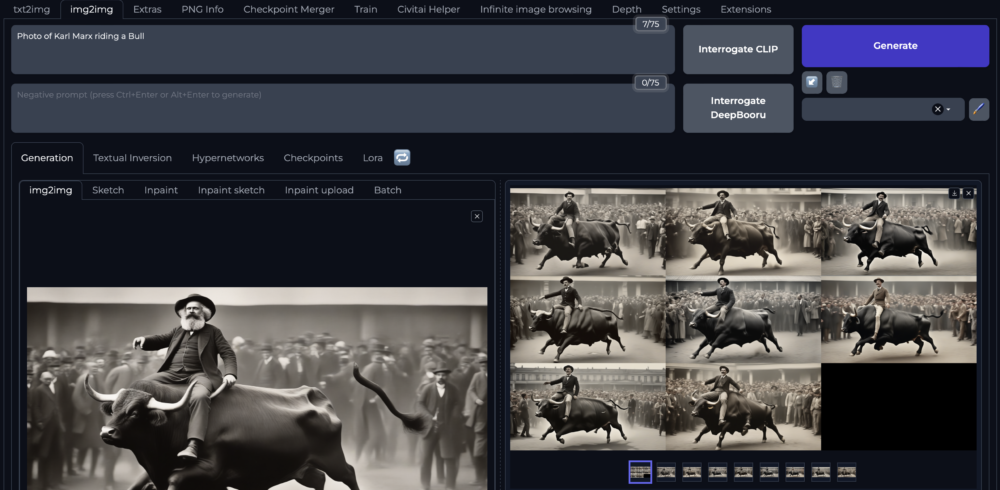
Man sieht die Ähnlichkeit in der Komposition und im Stil zum ersten Bild. Was in diesem Bild vollständig verloren ging ist Karl Marx.
Interrogate CLIP
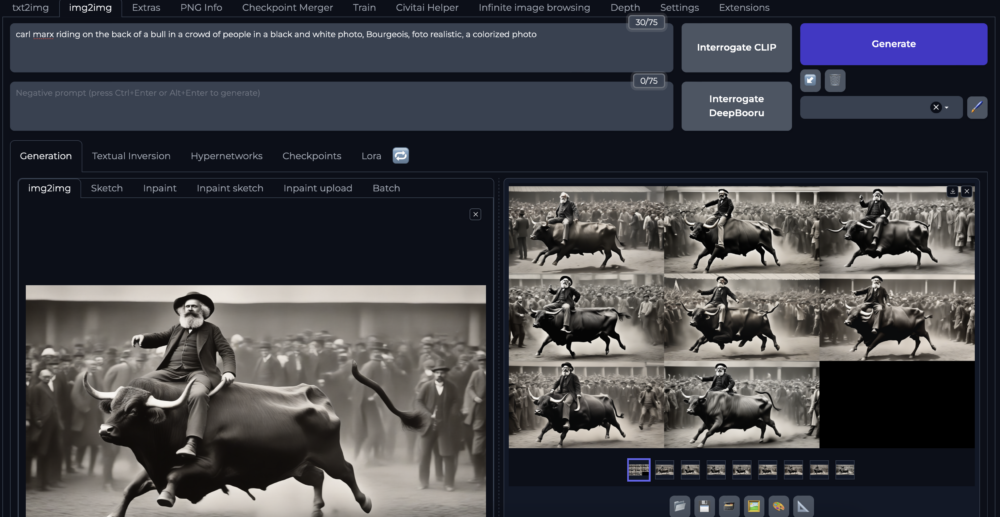
Mit einem Click auf Interrogate CLIP kannst du der Stable Diffusion WebUI einen Bildbeschrieb entlocken der evt. zu einem etwas präziseren Resultat führen kann. Hier sehen wir auch, dass in dem von CLIP generierten Bildbeschrieb Karl Marx keine Rolle spielt.
In meinem Beispiel unten habe ich diesen von CLIP vorgeschlagenen Prompt noch leicht modifiziert, um Carl Marx wieder im Spiel zu haben und danach eine neue Serie generiert.
Style: Modelle und LoRA`s
LoRAs (Low-Rank Adaptations) sind kleinere Modelle , die Du mit bestehenden Stable Diffusion Checkpoint-Modellen kombinieren kannst. Sie erlauben es ein Bestehendes Modell «Fine zu tunen». So kannst du neue Konzepte wie Styles, Subjekte und Objekte (je nach LoRA) in deinen generierten Bildern hinzufügen.
Diese neuen Konzepte fallen ganz grob unter 2 Kategorien:
- Stile
- z.B. Wasserfarbe, VHS Glitches, Comic Styles, Kartoffelstock, Glas ect.,
- Subjekte / Objekte
- Prominente Personen / Charaktere
- z.B. LiamGallagher, Rhianna / Lara Croft, Sauron ect.
Um ein LoRA zu aktivieren kannst du unter dem Tab LoRA ein entsprechendes LoRA aktivieren wichtig hierbei ist, dass das LoRA auch mit dem Basismodell kompatibel ist.
Im Falle dieses Beispiels versuche ich mittels der Taters LoRA eine aus Kartoffelstock gemachte Skulptur zu generieren: «Karl Marx auf einem Stier reitend». Wie schon erwähnt muss das Basismodell zum LoRA passen zum Teil werden auch bestimmte «Trigger Words» im Prompt gebraucht. In dem LoRA Taters ist dies: «made of mashed potatoes» oder «mashed potatoes and gravy».
In diesem Beispiel wurde folgendes festgelegt:
- Modell: realisticVisionV20_v20.safetensors
- LoRA: Taters V1
- Prompt: «made of mashed potatoes: Carl Marx riding a bull <lora:taters:1>»
- Seed: 1529031692
 Komposition: ControlNet
Komposition: ControlNet
ControlNet erlaubt dir verschiedene Möglichkeiten der Bildkomposition zu steuern. Je nach Modell gibt es verschiedene Optionen die dir ControlNet bietet zum Beispiel:
- Canny (weisse Umrisse auf schwarzem Grund)
- Open Pose (Skellet der Person im Bild)
- Depth maps (Tiefe im Bild als Graustufe je heller desto näher an der «Kamera»)
… und je nach Modell diverse andere.

Durch diese Controlnet Bildanalyse kann man nebst dem Prompt präzise Umrisse, Posen oder Tiefen Daten mit in den Generierungsprozess geben.
ControlNet Canny
Canny zeichnet einen weisse umriss Linien um Objekte: damit lassen sich auch Details zum Beispiel der Schattenwurf oder die Patches auf der Weste recht gut herausarbeiten und Replizieren. Über die Threshold kann die Detailstufe der Outlines bestimmt werden. Idealer Einsatz z.B. für Grafiken / Logos die Stylized werden sollten. Auch eigene Zeichnung können genutzt werden und als Basis für die generierten Bilder dienen.
Input:
- realisticVisionV20_v20.safetensors
- ControlNet: control_v11p_sd15_canny
- Prompt: «Carl Marx riding a bull»
- Seed: -1
Output:

Input:
- foddaxlPhotorealism_v45.safetensors
- ControlNet: diffusers_xl_depth_full
- Prompt: «Carl Marx riding a bull»
- Seed: -1
Output:
 ControlNet Depth maps
ControlNet Depth maps
Mit den Dephtmaps lassen sich prägnante Objekte sehr gut replizieren. In diesem Beispiel werden sowohl der Stier wie auch der Cowboy erkannt und eine grosse Ähnlichkeit in der Komposition reproduziert.
Input:
- Modell: realisticVisionV20_v20.safetensors
- ControlNet: control_v11f1p_sd15_depth
- Prompt: «Carl Marx riding a bull»
- Seed: 1529031692
Output:

Input:
- sd_xl_base_1.0_0.9vae.safetensors
- ControlNet: diffusers_xl_depth_full
- Prompt: «Carl Marx riding a bull»
- Seed: -1
Output:

ControlNet Open Pose
Open Pose erlaubt es dir Posen von Menschen, teilweise auch Gesichtern oder Handgesten zu extrahieren und diese Skelette danach zu nutzen, um Bilder zu generieren. So ist es möglich Bilder mit unterschiedlichsten Stilen in der selben Pose zu generieren. Da Stable Diffusion lediglich die Pose von dem Cowboy kennt, reimt es sich die Position von den Stieren in teilweise bizarren Konstellationen hinzu.
Input:
- realisticVisionV20_v20.safetensors
- ControlNet: control_v11p_sd15_openpose
- Prompt: «Carl Marx riding a bull»
- Seed: -1
Output:

Input:
- sd_xl_base_1.0_0.9vae.safetensors
- ControlNet: thibaud_xl_openpose
- Prompt: «Carl Marx riding a bull»
- Seed: -1
Output:
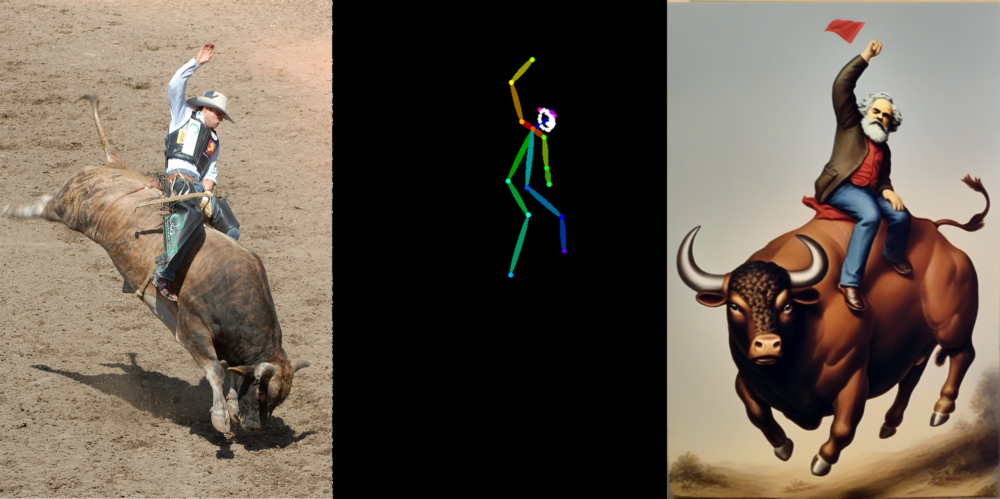
ControlNet in Kombination mit LoRA
Du kannst natürlich auch verschiedene LoRA Modelle mit dem ControlNet Kompiniert anwenden:
Input:
- realisticVisionV20_v20.safetensors
- ControlNet: control_v11f1p_sd15_depth
- LoRA: Taters
- Prompt: «made of mashed potatoes: Carl Marx riding a bull <lora:taters:1>»
- Seed: -1
Output:

Input:
- Model: v1-5-pruned.safetensors
- ControlNet: control_v11f1p_sd15_depth
- LoRA: VHS3
- Prompt: «VHS, glitch, Carl Marx riding a bull <lora:VHS3:1>»
- Seed: -1
Output: