Whisper OpenAI – Transkription

Du brauchst eine Transkription aus einem Audiofile als Protokoll einer Sitzung, Untertitel für dein Video, oder du willst dir eine Audiospur ins Englische übersetzen lassen? Dann ist dieses Modell extrem hilfreich! Hier zeigen wir dir wie du dieses Modell auf unserem Machine Learning PC laufen lassen kannst und was du für Outputs erwarten darfst.
Prolog
Open AI hat Whisper Opensource zur Verfügung gestellt. Die Software ist auf unserer ML-Workstation verfügbar kann aber auch auf deinem Laptop (z.B. einem M1 Macbook) Problemlos installiert und genutzt werden. Whisper erlaubt dir die Extraktion von gesprochener Sprache aus Audiofiles und Videofiles. Du kannst damit also z.B. eine Transkription von gesprochenem Text in ein Textfile machen oder Übersetzung von verschiedenen Sprachen ins englische Generieren oder deinem Video schnell Untertitel verpassen. Es erkennt auch wenn es sich bei Aufnahmen nur um Hintergrundgeräusche (z.B. Musik) handelt und transkribiert nur die gesprochene Sprache.
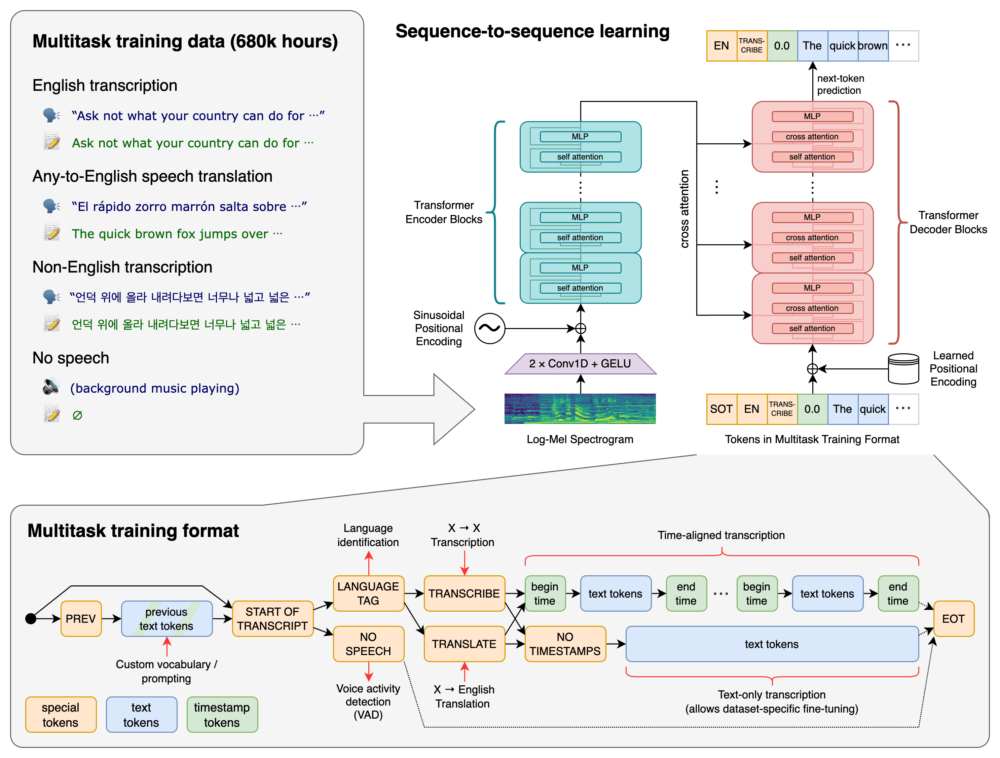
Welche Sprachen unterstützt Whisper
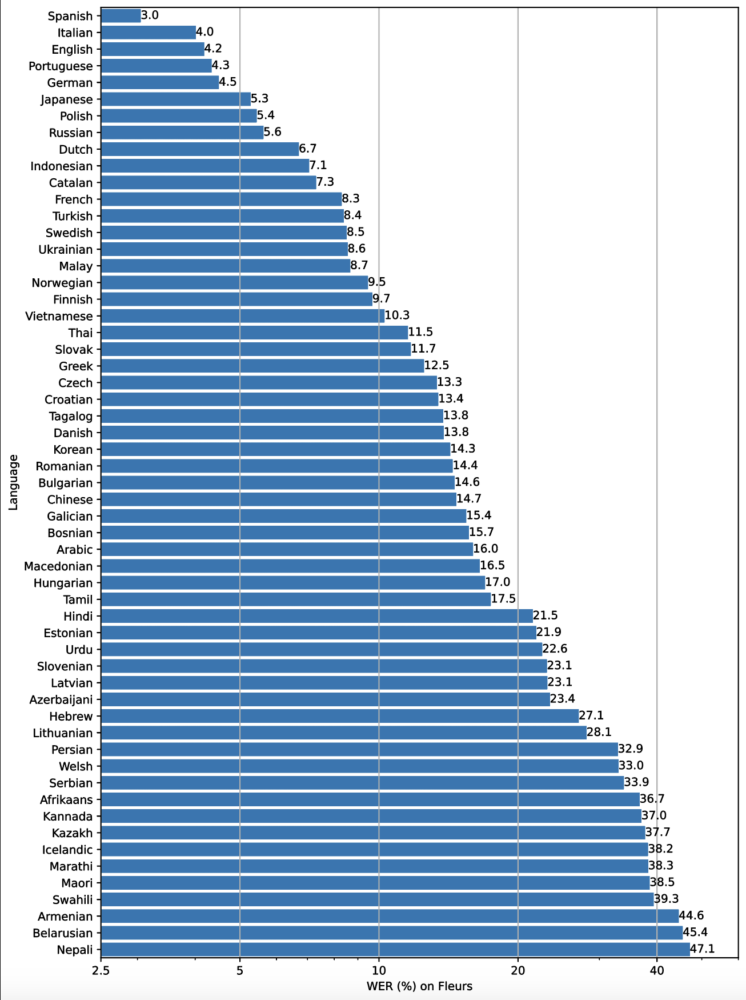
Die Leistung von Whisper ist je nach Sprache sehr unterschiedlich. Die folgende Abbildung zeigt eine Aufschlüsselung der WER (Word Error Rate) nach Sprachen für den Fleurs-Datensatz unter Verwendung des large-v2-Modells (je kleiner die Zahlen, desto besser die Leistung, d.h. weniger Fehler in der Transkription).
Die komplette Liste der unterstützten Sprachen:
Afrikaans, Albanian, Amharic, Arabic, Armenian, Assamese, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bosnian, Breton, Bulgarian, Burmese, Castilian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Faroese, Finnish, Flemish, French, Galician, Georgian, German, Greek, Gujarati, Haitian, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Lao, Latin, Latvian, Letzeburgesch, Lingala, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Maori, Marathi, Moldavian, Moldovan, Mongolian, Myanmar, Nepali, Norwegian, Nynorsk, Occitan, Panjabi, Pashto, Persian, Polish, Portuguese, Punjabi, Pushto, Romanian, Russian, Sanskrit, Serbian, Shona, Sindhi, Sinhala, Sinhalese, Slovak, Slovenian, Somali, Spanish, Sundanese, Swahili, Swedish, Tagalog, Tajik, Tamil, Tatar, Telugu, Thai, Tibetan, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Valencian, Vietnamese, Welsh, Yiddish, und Yoruba.
Whisper nutzen
Input Datei
Um Whisper auf unserem ML Rechner nutzen zu können brauchst du eine Datei die du transkribieren, übersetzen oder untertiteln möchtest. In unseren Beispielen nehmen wir 3 verschiedene Sprachen respektive Dialekte mit unterschiedlichen Hintergrundgeräuschen:
- Englisch:
- Creatures Comforts
- Epic Rap Battle of History Bill Gates vs. Steve Jobs (Comedy Rap mit Hintergrundmusik)
- Deutsch
- Zungenbrecher Poetry-slam mit Zungenbrechern in Deutsch
- Schweizerdeutsch Dialekt
- Tschugger – Trailer in Englisch und Walliser Dialekt.
- Schnitzelbank in Basler Dialekt.
Dateiformate
Folgende Formate werden unterstützt:
- m4a
- mp3
- webm
- mp4
- mpga
- wave
- mpeg
Whisper auf Datei anwenden
Auf unserem ML Rechner öffnest du das Terminal und lädst deine Datei folgender Massen:
cd home/Documents/Applications/whisper
conda activate whisper
Whisper startest du nun folgender massen:
whisper home/Documents/MyFolder/MyVideo.mp4 --output_dir home/Documents/MyVideoFolder/Whisper/MyFolder
Wir starten Whisper im Terminal indem wir es mit «whisper» aufrufen, danach braucht es einen Pfad wo whisper dein Video / Audio File finden kann und zum schluss geben wir Ihm nach dem «–output_dir» einen weiteren Pfad für den output mit.
Whisper extrahiert nun aus deiner Datei folgende Outputs:
- ein json
- ein srt (Untertitel File)
- ein tsv (Tab Separated Values -> ähnlich einem csv (Comma Separated Values)
- txt (reiner Text)
- vtt (Web Video Text Tracks File -> Text mit Zeitangaben)
Output Beispiele
Sämtliche der folgenden Beispiele sind die generierten Untertitel aus Whisper – es wurden keine Veränderungen an den Transkriptionen oder dem Timing gemacht. Diese Beispiele sind dazu gedacht um die Potenziale wie auch Anfälligkeiten zu demonstrieren.
Creatures Comforts
Englische Sprache, wenig Hintergrundgeräusche – fast Perfekt
Epic Rapbattle of History
Ebenfalls Englisch mit starkem Hintergrundgeräusch (Musik / Beat): Hier wurde am Anfang vermutlich der Beat als Sprach identifiziert und übersetzt.
Zungenbrecher Poetry Slam
Deutsch aber komplizierte Sätze mit diversen ähnlich klingenden Worten. Trotzdem ist Whisper meistens präzise.
Tschugger
Schweizer Dialekte sind vermutlich nicht ein riesiger Teil des Trainingsdatensatzes von Whisper, dennoch finde ich es ziemlich spannend wie viel Whisper dennoch «aufschnappt» – Hier müsste aber Definitiv noch eine Person die Untertitel korrigieren.
Schnitzelbank
Dialekte sind und bleiben eine Herausforderung für OpenAI`s Whisper…