Train Stable Diffusion with Replicate

In diesem Recipie schauen wir uns an, wie wir ein Stable Diffusion Modell mit Replicate trainieren können, um einen bestimmten Stil zu erzeugen. Was ist ein LoRA? Welche Daten braucht es? Was sind die Vor- und Nachteile von Replicate? Wie lange dauert es ein LoRA zu trainieren?
Upcoming Event:
Was ist ein LoRA?
LoRAs (Low-Rank Adaptations) sind kleinere Modelle, die du mit bestehenden Stable Diffusion Modellen kombinieren kannst. Sie erlauben es ein Bestehendes Modell «fine zu tunen». So kannst du neue Konzepte wie Styles, Subjekte und Objekte (je nach LoRA) in deinen generierten Bildern hinzufügen. Die Methode zum Training spezieller Stile / Konzepte, die wir nutzen, ist hier ziemlich ausführlich beschrieben: Dreambooth.
Diese neuen Konzepte fallen ganz grob unter 2 Kategorien:
- Stile
- z.B. Wasserfarbe, VHS Glitches, Comic Styles, Glas-Optik ect.,
- Subjekte / Objekte
- Prominente Personen / Charaktere
- z.B. Liam Gallagher, Rhianna / Lara Croft, Sauron ect.
Um ein LoRA zu aktivieren kannst du unter dem Tab LoRA ein entsprechendes LoRA aktivieren wichtig hierbei ist, dass das LoRA auch mit dem Basismodell kompatibel ist.
Beispiele für die Anwendung von LoRAs findest du hier: Stable Diffusion – webUI
Was für Daten brauche ich, um ein eigenes LoRA zu trainieren?
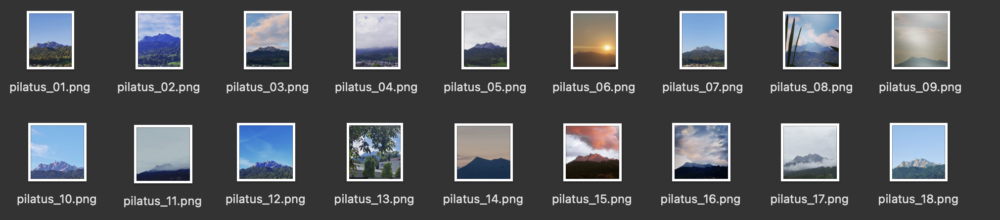
Du brauchst dafür ein Dataset von ca. 10-30 Bildern. Dies können Bilder eines bestimmten Stils, eines Objekts oder z.B. des Gesichts einer Person (Selfies) sein. Im nachfolgenden Beispiel wurde ein Dataset mit 50 Bildern des Pilatus genutzt.
 Dataset-Ethik
Dataset-Ethik
Bei Datensätzen für KI-Trainings solltest du beachten, dass es gewisse ethische Probleme geben kann.
Fürs Training unbedenklich sind Bilder:
- die du selbst gemacht hast, dir selbst gehören, deine Autorschaft tragen
- die im Besitz von Personen die dir klar und deutlich ihre Zustimmung gegeben haben
- die unter Creative Commons (CC0) veröffentlicht wurden
- deren Copyright schon länger abgelaufen ist oder die nicht unters Urheberrecht fallen
Dies ist besonders wichtig, da deine Replicate-Modelle auf einem externen Server gehostet werden.
Über Replicate
Was ist Replicate?
Replicate ist eine Plattform, die verschiedenste Tools für die Arbeit mit AI zur anbietet. Darunter findet sich auch die Möglichkeit, das Stable-Diffusion-XL-Model durch ein LoRA zu verfeinern. Replicate stellt seinen Nutzern ausserdem Serverspace zur Verfügung, um Modelle zu trainieren und anschliessend zu hosten.
Vorteile
Das Training mit Replicate ist einfach zu erlernen. Die Plattform will ML-Tools verständlich uns zugänglich gestalten. Zudem kannst du auf die Hardware des Anbieters zugreifen. Für die Erstellung eines Modelles heisst das, dass du komplexe und rechenintensive Arbeiten innerhalb kürzester Zeit durchführen kannst. Ausserdem kannst du mehrere Trainings gleichzeitig laufen lassen. Bei der späteren Nutzung deines Modelles bedeutet dieser Vorteil, dass deine Projekte online zugänglich sein werden. Du wirst also von überall auf sie zugreifen und sie unkompliziert mit anderen teilen können.
Nachteile
In der Online-Natur des Services liegt aber auch sein grösster Nachteil. Daten und Modelle, die du auf Replicate verarbeitest und erstellst, landen auf den Servern grosser, kommerzieller Firmen. Es ist insbesondere wichtig, sich darüber im Klaren zu sein, wenn du mit sensiblen Daten (Gesichter, Copyright-geschützes Material, etc.) arbeitest. Modelle, die du auf Replicate erstellst, können ausserdem nicht gelöscht werden.
Zudem ist Replicate eine kostenpflichtige (wenn auch sehr erschwingliche) Lösung.
Wie viel Zeit und Geld braucht es, ein LoRA mit Replicate zu trainieren?
Das Training mit Replicate dauert um die 10 Minuten. Der ganze Vorgang, inklusive dem Generieren von 30 Bildern wird dich ca. 0.90 Franken kosten. Genaue Angaben zum Pricing findest du hier.
Training mit Replicate
Du hast einen Datensatz von 10-30 Bildern und willst ein Training versuchen? Let’s Go!
Python
In diesem Beispiel werden wir ein Python-Scrip nutzen, um unser Training zu initiieren. Es gibt die Möglichkeit, ein Modell durch andere Scripts, beispielsweisse in den Sprachen JavaScript oder Swift, zu erstellen. Eine Übersicht dazu findest du in der Dokumentation.
Stelle als erstes sicher, dass du Python auf deinem PC installiert hast. Öffne dazu ein Terminal-Fenster und führe zuerst die Befehle python –version und python3 –version aus. wenn du bei beiden Inputs die Meldung command not found zurückerhältst, musst du Python erst noch herunterladen.
 Dataset Vorbereitung
Dataset Vorbereitung
Zippe dein Dataset und lade es auf einen Server hoch (nicht lokal auf deiner Maschine). Das kann zum Beispiel über das Webhosting deiner persönlichen Website sein. Falls du keinen Zugang zu einem solchen Service hast, kannst du deine Bilder auch auf deinem GitHub-Account hosten.
LoRA-Training
Replicate
Um Replicate zu nutzen, brauchst du als erstes einen GitHub-Account. Mit dem meldest du dich anschliessend auf der Replicate-Website an. Da Replicate ein kostenpflichtiger Service ist, musst du zusätzlich auf deinem Profil eine Debit- oder Kreditkarte hinterlegen.
Danach kann es an die Vorbereitung des eigentlichen Trainings gehen. Erstelle dazu zuerst einen API-Token. Hier bestimmst du das Trigger-Wort, welches du später verwenden wirst, um dein LoRA zu aktivieren. In unserem Beispiel bestimme ich das Wort «PILATUS» als Token.
 Nachdem du den Token geschaffen hast, wird eine Token-ID erstellt, die du später in dein Script einfügen wirst.
Nachdem du den Token geschaffen hast, wird eine Token-ID erstellt, die du später in dein Script einfügen wirst.
 Als nächstes erstellst du über dein Dashboard unter «Models» ein neues Model.
Als nächstes erstellst du über dein Dashboard unter «Models» ein neues Model.
 Hier gibst du deinem neuen Modell zuerst einen Namen. Der gewählte Name darf nur Kleinbuchstaben, Zahlen, Bindestriche, Unterstriche oder Punkte enthalten und darf nicht mit einem Bindestrich, Unterstrich oder Punkt beginnen oder enden.
Hier gibst du deinem neuen Modell zuerst einen Namen. Der gewählte Name darf nur Kleinbuchstaben, Zahlen, Bindestriche, Unterstriche oder Punkte enthalten und darf nicht mit einem Bindestrich, Unterstrich oder Punkt beginnen oder enden.
Danach wählst du aus, ob dein Modell privat oder öffentlich zugänglich sein soll. Wenn du dich für die Option «Public» entscheidest, wird dein LoRA von anderen Personen eingesehen und genutzt werden können.
Bei der Hardware ist die Option «Nvidia A40 (Large) GPU» grundsätzlich ein guter Kompromiss zwischen Leistung und Kosten. Du kannst dich natürlich auch genauer über das Pricing und die Specs der entsprechenden Hardware informieren und darauf aufbauend die beste Option für dein Projekt auswählen.
Beim letzten Drop-Down-Menü wählen wir die Art des geplanten Modells. In unserem Fall erstellen wir ein «Fine-tuned image model (e.g. SDXL)».
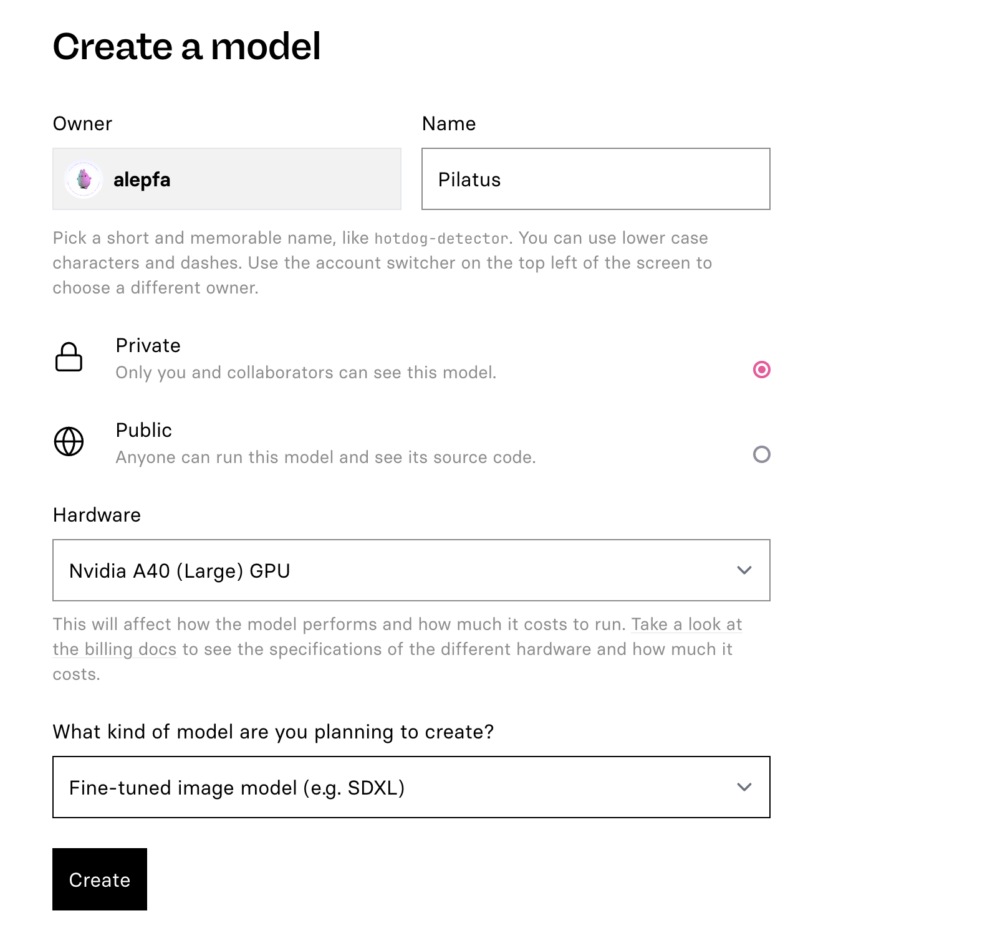 Bestätige deine Auswahl mit «Create». Anschliessend kannst du über das Dashboard zurück zu deinen «Models». Kopiere hier den Pfad (Username/Projektname) deines Projektes – du wirst ihn ebenfalls für dein Python-Sript benötigen.
Bestätige deine Auswahl mit «Create». Anschliessend kannst du über das Dashboard zurück zu deinen «Models». Kopiere hier den Pfad (Username/Projektname) deines Projektes – du wirst ihn ebenfalls für dein Python-Sript benötigen.
Python-Code
Als nächstes ladest du den Code für das Training hier herunter. Bevor wir diesen anpassen können, müssen wir noch die Replicate-Library für Python installieren. Öffne dazu ein neues Terminal-Fenster. Hier gibst du den Befehl pip install replicate (bei Python Version 2 oder älter) oder pip3 install replicate (bei Python Version 3) ein. Nachdem das Packet installiert wurde, kannst du das Replicate.py-Script in der Python IDE (IDLE), oder einer anderen Umgebung deiner Wahl öffnen.
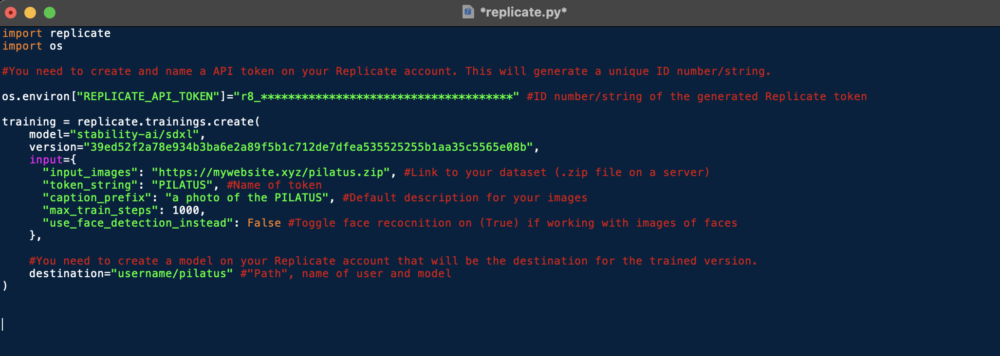 Hier passt du nun folgende Variablen an:
Hier passt du nun folgende Variablen an:
- [«REPLICATE_API_TOKEN»]: Hier fügst du die ID deines Tokens ein.
- input_images: Hier fügst du den Pfad zu deinem Dataset ein.
- token_string: Hier fügst du den Namen deines Tokens ein.
- caption_prefix: Hier legst du fest, wie deine Bilder beschriftet werden. Inkorporiere den Namen deines Tokens in die Beschreibung.
- use_face_detection_instead: Wenn du mit Fotos von Gesichtern arbeitest, ändere diese Variable zu True.
- destination: Hier fügst du den Pfad (Username/Projektname) deines Modells ein.
Im Anschluss kannst du das Scrip durch Run > Run Module starten.
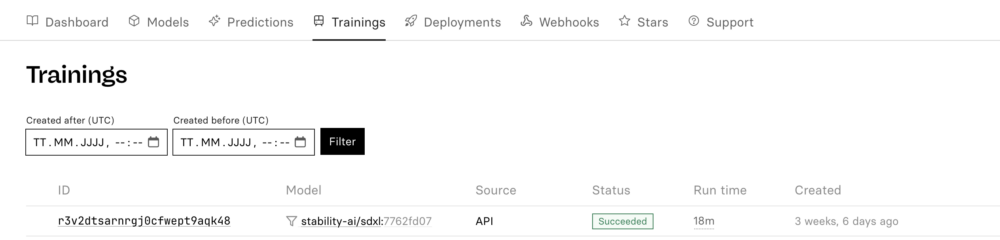
Sobald dein Script ohne Fehler ausgeführt wurde, kannst du den Fortschritt deines Trainings über dein Dashboard unter «Trainings» verfolgen.
 Anwendung des Modells
Anwendung des Modells
Wenn das Training abgeschlossen ist (Status: Succeeded), kannst du dein Modell über dein Dashboard unter «Models» aufrufen.
 Prompt
Prompt
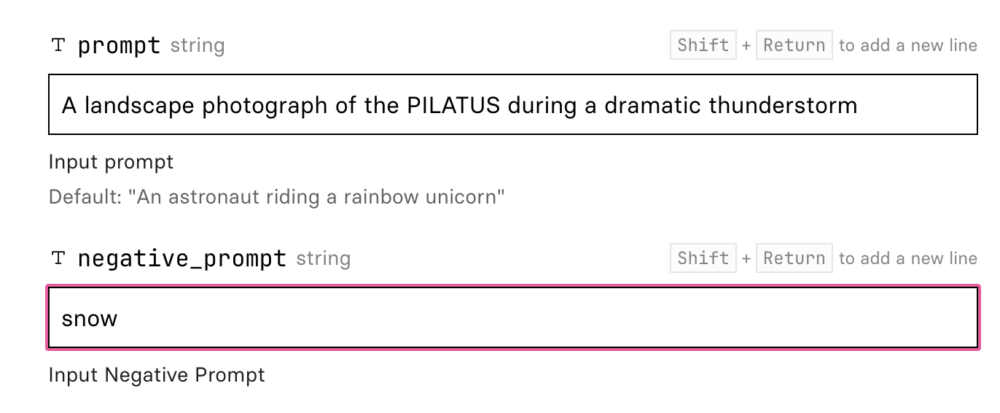
Da wir mit einem Text-to-Language-Modell arbeiten, generieren wir unsere Bilder durch einen Prompt; ein Text, in dem wir das gewünschte Resultat beschreiben. Wichtig ist, dass du beim prompt den vorher bestimmten Token, in unserem Fall «PILATUS», einbaust. So wird das LoRA aktiviert. Es hilft ausserdem, wenn du deinen Prompt zudem durch Synonyme und assoziierte Stichworte in die gewünschte Richtung «lenkst». Im Falle des Pilatus-Modelles könnten das Inputs wie «Mountain» oder «Landscape» sein.
 Weitere Parameter
Weitere Parameter
Du kannst deinen Output noch durch die Anpassung (unter anderem) folgender Parameter verfeinern:
- negative_prompt: Hier legst du fest, welche Elemente du NICHT auf dem generierten Bild wünschst.
- image: Hier kannst du ein Bild hochladen, welches dann als Ausgangslage für dein Modell genutzt wird.
- width & height: Die gewünschte Breite und Höhe des generierten Bildes, in Pixel.
- num_outputs: Die gewünschte Anzahl Outputs (1-4).
- prompt_strength: Wenn du bei image ein Bild einfügst, kannst du hier bestimmen, wie stark dein Prompt Einfluss darauf nehmen soll (0-1).
- lora_scale: Hier legst du fest, wie stark das Finetuning durch dein eigenes Dataset Einfluss auf das generierte Bild nehmen soll (0-1).
Danach clickst du nur noch auf «Run»!
Die Resultate
Tada







