Problemstellung
Convolutional Neural Networks (CNN) werden häufig für die Bildverarbeitung, speziell für die Detektion von Objekten, eingesetzt. Ein an der HSLU entwickelter Low-Cost CNN-Beschleuniger soll dabei helfen, diese auf eingebettete Systeme mit wenig Rechenleistung zu bringen. Die Zielhardware besteht aus einer Kombination aus Processing System (CPU) und Programmierbarer Logik (PL). In dieser Arbeit wurde untersucht, ob ein Object Detector CNN mit dieser Methode beschleunigt werden kann.
Lösungskonzept
Ein Object Detector CNN wird ausgewählt und trainiert. Die «Mean Average Precision» (mAP) des Netzwerks wird berechnet, um die Genauigkeit der Detektionen zu quantisieren. Durch die Berechnung des Verbrauchs an Hardware-Ressourcen (LUT, FF, DSP, BRAM) auf der PL wird berechnet, wie schnell ein Bild verarbeitet werden kann. Weitere mögliche Engpässe, welche die Geschwindigkeit der Verarbeitung einschränken könnten, werden identifiziert und analysiert.
Realisierung
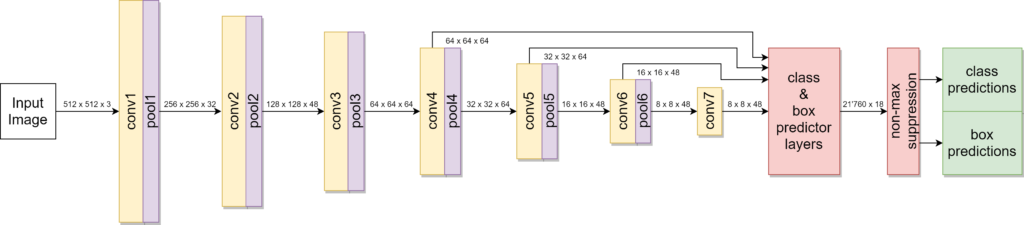
Die Single-Shot MultiBox Detector (SSD) Architektur wurde gewählt und für 176 Epochen (ca. 24h auf Nvidia RTX 2080 Ti) trainiert. Um die Ausführung des Netzwerks (SSD-7) mit dem Hardware-Beschleuniger zu ermöglichen, wurde es in eine binär approximierte Form überführt. In dieser Form konnte auch der Verbrauch an Hardware-Ressourcen und die Verarbeitungszeit für verschiedene Konfigurationen berechnet werden. Der verfügbare Speicher des Hardware-Beschleunigers, die Aktivierungsfunktion und die Berechnungen auf der CPU wurden als potentielle Engpässe genauer untersucht.
Ergebnisse
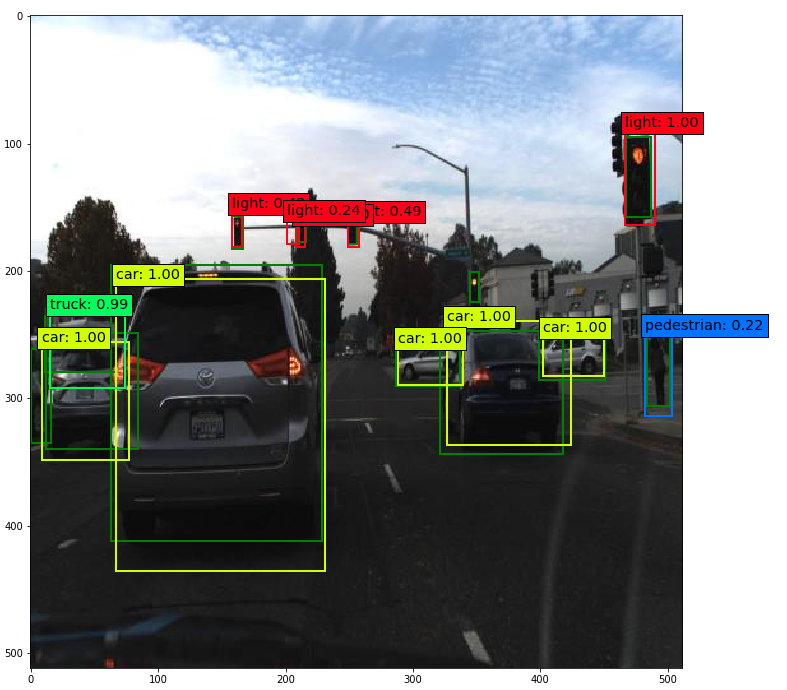
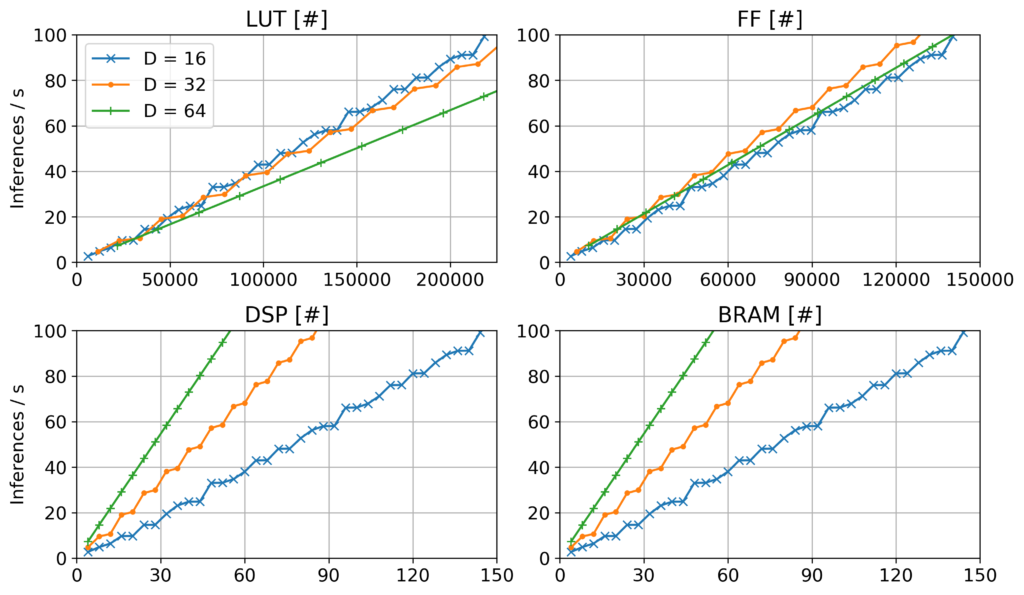
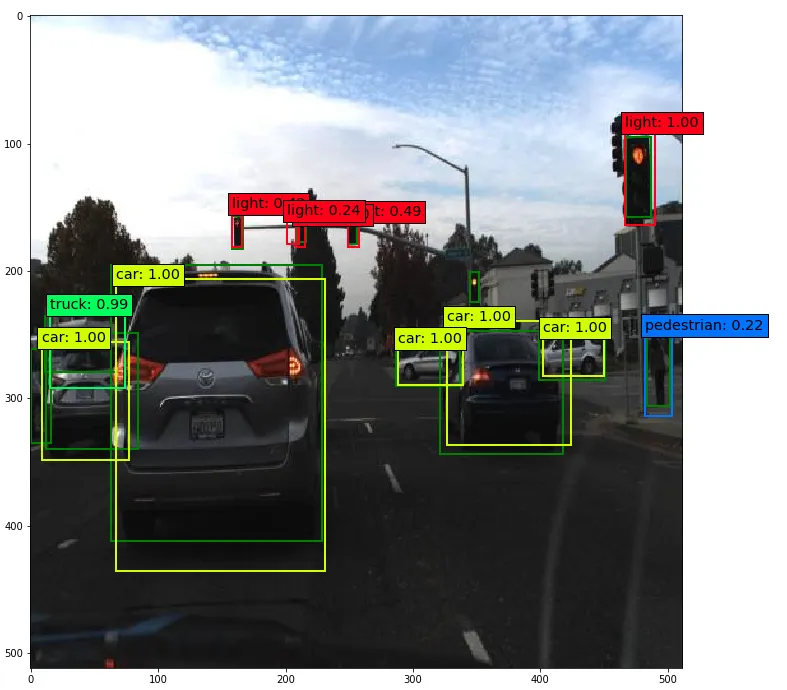
Das trainierte SSD-Netzwerk erreicht eine mAP von 0.308. In der binär approximierten Form mit vier Binärtensoren pro Floating-Point-Tensor sinkt dieser Wert nur geringfügig auf 0.303. Die maximale Verarbeitungsgeschwindigkeit mit einer Mid-Range Hardware (Xilinx XC7Z045) beträgt 99.23 und mit einer Low-End Hardware (Xilinx XC7Z010) 6.54 Inferenzen pro Sekunde. Da die PL nicht genügend Speicherplatz zur Verfügung stellt, muss das Bild in mehrere Kacheln unterteilt, verarbeitet und anschliessend wieder zusammengefügt werden. Eine 1 GHz CPU benötigt nur 181 µs pro Bild für die Non-Maximum-Suppression Stage, welche nicht auf der PL ausgeführt werden kann, und limitiert somit die Verarbeitungsgeschwindigkeit nicht.
Studienbetreuer Prof. Dr. Jürgen Wassner
Preisstifter Hochschule Luzern, Institut für Elektrotechnik, CC ISN