Mirror, mirror on the wall, who’s the fairest picture of them all?
An approach to evaluate the quality of conditionally generated images of faces. What happens when people wear masks in times of pandemics such as COVID-19? First, it helps the society in preventing the virus from further spreading. Second, it provides a feeling of protection as people feel safer when wearing masks. Third, it causes serious issues in various sections of deep learning in computer vision; specifically in the area of image detection and face recognition.
Image generation models might be a solution to the problem as facial features covered by masks can be recreated by means of deep learning. But are these models suited to this very problem? And how well do they represent the quality of the pictures? Let’s find it out with our approach to evalu-ate the quality of conditionally generated images of faces.
Previous studies discovered that wearing facial masks can cause the error rate of facial recognition algorithms to increase up to 50%. Apple’s iPhones were having issues with their Face IDs recently as people’s faces couldn’t be recognized anymore as the result of wearing masks. Parts of the face such as nose, mouth or the eyes are essential features when recognizing and detecting a person’s face in computer vision. The problem outlined above and the fact that we wanted to contribute our part against the current COVID-19 issue led us to the idea to generate missing facial features in images with the help of image generating models.
A previous project of ours in the module Deep Learning in Vision conducted by Prof. Dr. Mirko Birbaumer included the generation of facial features by Generative Adversarial Networks (GANs), where we trained a model to generate and fill missing eye areas in images. However, we hadn’t been able to quantitatively evaluate the quality of our GAN and its generated images such as the ‘reconstructed’ faces. This was reason enough to build an algorithm in order to measure the quality of generated images. Consequently, our project team decided to find an approach to evaluate the quality of conditionally generated images of faces and submit it as a research paper ‘An approach to evaluate the quality of conditionally generated images of faces’. The output of our research paper consists of an approach with which one can not only assess the quality of an image generation model and its corresponding generated images, yet also allows to measure how much a generated image adds value for image classification. The research paper has been submitted just recently and we are happy to present and outline our approach as well as some of our findings in this blog post. The following paragraphs will first introduce our GAN as it is the main source for the input images of our evaluation approach. Then, our evaluation approach, which is used to measure the quality of the images produced by our GAN, is described.
About our Generative Adversarial Network
As part of our module Deep Learning in Vision in the autumn semester 2020, we created a conditional GAN in order to generate facial parts in images, where those were missing. For example, our goal was to recreate the eye-parts of faces in images that were covered by sunglasses. In order to do so, we provided images of faces with a black bar as input for our GAN, which was previously trained on high quality face images. The aim of the GAN was then to reconstruct the eye parts in images by filling the black bar with a recreation of the eyes.
Our GAN performed relatively well after roughly 60 hours of training on our virtual machine. Some examples of reconstructed eye parts in images can be seen in figure 1 below, where in each column the image in the first row was the source image, the image in the second row the reconstructed (output) image and in the third row the original image.

The generated pictures were promising, yet at that time we had no quantitative metric in evaluating the goodness of our GAN model resp. its generated images. Therefore, we decided to find a solution on how to come up with an impartial, quantitative measure.
Inception Score and Face Recognition
Literature suggests two main scores in measuring the quality of image generation models, namely the Inception score and the Fréchet inception distance. We decided to apply the former on our model. The Inception score is an objective metric that calculates a score from a sample of images and quantifies how realistic the GAN output is. In other words, it measures how close the generated image comes to the original image. Besides the Inception score, we wanted to assess whether the face images with generated eye-parts were recognizable by means of image classification. For that, we have used the face recognition tool and its measures to identify whether faces of generated images can be identified.
To sum up, the Inception score and face recognition score were the two underlying measures on which we built our approach to evaluate the quality of conditionally generated images of faces. Having said that, our approach contained several different work packages that needed to be tackled. Thus, we spontaneously decided to organize our own virtual hackathon during the Pentecost weekend lasting from Sunday, May 23rd to Monday, 24th 2021. Below is a picture of the three of us during a video conference call back then.
We worked mainly on two big work packages during our hackathon. One part of the team focused on applying the Inception score on our GAN and the other team was building the data pipeline for our face recognition procedure. The various working packages and the corresponding tasks were broken down into a diagram that helped the visualization and the monitoring of our project. Figure 2 below represents the process flow to calculate the face recognition score.
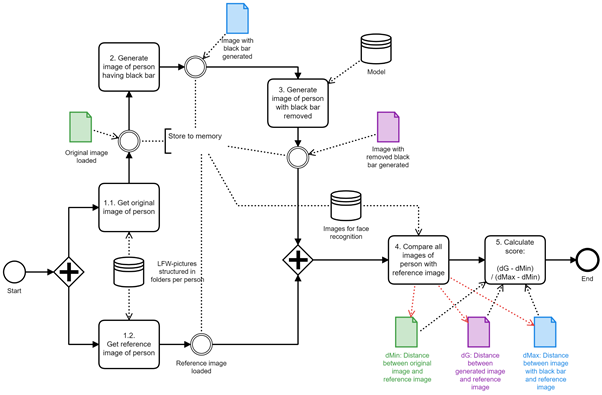
Images are taken from the Labeled Faces in the Wild (LFW) dataset. For each face detected, an original copy from the image is taken as the original image, and a second one, on which black bars are placed over the eyes as the source image (see steps 1.1 and 2; figure 2). The loaded model (in our case it was the pre-created GAN model) then tries to generate an image from the image with the bars that resembles the original one as good as possible (steps 3; figure 2).
As part of the subsequent quality-evaluation of the generated image, the dissimilarity between that image and a reference image, also loaded from the LFW dataset (step 1.2; figure 2), is calculated. The reference image is simply a separate image from the same person. The dissimilarity between the generated and the reference image is indicated by a score; the lower the score, the better the quality of the generated image. To define the lowest point in the range of the possible score, the dissimilarity between the original image and reference image is measured as well. In addition, the distance between source image and reference image is calculated to determine the highest point in the range (step 4 and 5; figure 2). From the resulting three values, the final relative score of an image is drawn using the following formula:
Final relative score of a generated image = (dG – dMin) / (dMax – dMin)

Results
The following paragraph highlights the results from our evaluation approach taking the generated images from our GAN as an example. It is crucial to mention that our evaluation tool simply provides an overall state of our GAN model and thus quantifies how well our GAN model generates images – or more specifically, missing facial features in face images.
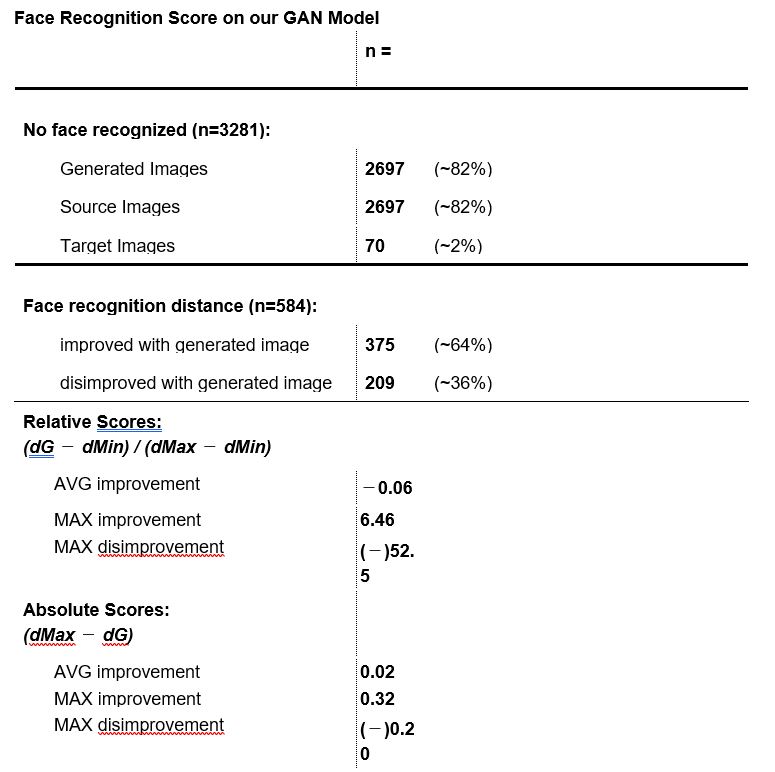
The first results from our approach to evaluate the quality of conditionally generated images are very promising from our point of view. The Inception score for our GAN and thus of the generated images is at 2.21 and therefore roughly the same as the one for our target images. Thus, this suggests that our GAN generates images that are equally diverse (have approx. the same variances) as of our target images. The difference between generated and source images is 0.2. Hence, it can be inferred that the generated images add value to the Inception score. The standard deviation is at 0.07, yet this is due to our relatively low image sample (n = 3281). Literature suggests large data samples in order to get a representable Inception score. Our dataset only provided 3281 images where image pairs of original and reference images could be gathered.

The results of the face recognition tool in table 2 provide an overall view over the quality of our GAN model and consequently its generated images according to our evaluation approach described above. Overall, the same amount in generated images and source images are recognized (18%). This rather low number states that faces in generated images are still far more difficult to detect than faces in original images. Generally, one has to acknowledge that image recognition, in particular face recognition, is a complex task. For the faces that were recognized, about two-third (375) showed an improvement whilst about one-third (209) showed a disimprovement while calculating the face recognition score. In other words: in 64% of the cases, the recognition of the face – specifically of the generated eye-parts – was improved. The rather low maximum improvement score compared with the high disimprovement of (−)52.5 states that image pairs with an already close distance between distances (dMax – dMin) perform worse in the evaluation. The Max Improvement value in the absolute scores reveal that in one case (see figure 4 below), the generated eye-parts of an image contributed to an increase of 0.32 in information and thus added-value to the face recognition. The average improvement of the absolute score over all images is positive at 0.02, which states that generated images provide overall more information to the face recognition than the source images.
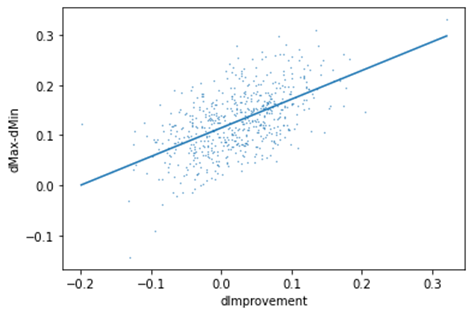
Our findings suggest a positive correlation between the dissimilarity (dMax − dMin) and the improvement (dImprovement resp. dissimilarity dMax – dG) of the face recognition (see figure 3). This implies that for original images, in which the eyes are essential for the face recognition, yet are covered by the black bar, our generated images provide a slight improvement in the face recognition. Note that the face recognition is trained on real world images. In our case however, we used images with generated facial parts (eye-parts) in it. We assume that by further training the face recognition model based on generated images, the overall accuracy can be increased and result in higher improvement.
dMin)
Examples
As described in the result section, some image pairs were well recognized by the face recognition tool and thus received a rather high-quality metric, whereas other image pairs could not be recognized at all. Some of the images are presented as examples below. Figure 4 for instance scored relatively well in the absolute measurement improvement metrics (dMax – dG = 0.32) as the generated eyes are similar to the original ones. Interestingly, the disturbance in the picture in form of the tennis ball did not significantly impact the eye-parts generation. Figure 5 presents an image where our GAN model generated the eyes and eyebrows differently to the original image. Thus, the face recognition tool and consequently our evaluation approach scored this as a disimprovement of 0.20. The disimprovment of 0.20 results from the dissimilarity between the dG and dMax. In that case, the difference between the generated image and the reference image (dG) was larger than the distance between source image with black bar and reference image (dMax). Figure 6 instead presents an example where a face does not get recognized from the generated image and thus receives no score. This is due to the fact that the eyes generated in the generated image point to a different direction than the eyes do in the original image (similar to figure 5) and the dissimilarity between reference image and generated image may be too high. Overall, the examples described provide proof for the importance of facial features such as the eye parts in the case of image recognition such as face detection.





Figure 6: This face was only recognized on the original and the reference image, but not on the source and generated image. Consequently, no scores could be calculated. The eyes on the generated image point in a different direction than on the original image
Once more we want to emphasize that the results outlined above and the examples presented are simply the quality evaluation of our GAN model and its generated images having applied our evaluation tool including the face recognition scores on it. Applying our evaluation approach on further image generation models such as further trained GANs or transformers would obviously result in different findings.
In conclusion, we are very satisfied with our project and the corresponding research paper. The aim of this paper was to build a model with which to quantitatively analyze the quality of image generation models and its generated images using face recognition as classification method. Based on the Inception score and the face recognition algorithm, we have created a tool that allows not only to validate different image generation models with each other, yet also provides a mean to quantify how much value-added a generated face image can create compared to images with missing (for example covered) facial features.
This project delivered two key insights. First, it confirmed that our evaluation approach works. Second, it provided a status quo on how well our trained GAN performs in generating distinct images. Additionally, our evaluation model further serves to assess whether generated facial features by our GAN, such as the eye-parts, can improve the correct classification in face recognition. Generally, the promising results of our GAN’s evaluation suggest that image generation models are a feasible tool to recreate missing facial features of an image and thus may be a viable option to counteract difficulties in face detection issues nowadays, where people almost everywhere wear facial masks. Finally, our approach to evaluate the quality of conditionally generated images of faces can be used as a basis for further image classification challenges and can thus be applied in various areas of computer vision.
Authors:

Info-Events
Start your career with the MSc in Applied Information and Data Science now!
Join one of our online Info-Events:
Monday, 10 August 2026 (Online, English)
Monday, 7 September 2026 (Online, German)
Monday, 5 October 2026 (Online, English)
Monday, 2 November 2026 (Online, English)
Friday, 27 November 2026 (Online, German)
Monday, 11 January 2026 (Online, English)
Programme Information | Contact | Info-Events
Interested in the MSc in Applied Information and Data Science?
Visit our Info-Events. We look forward to meeting you!
Please contact us if you have any questions about your studies:
Tel.: +41 41 228 41 30
Email: master.ids@hslu.ch
Further links to the programme:
→ Generalist profile
→ Career profiles and study insights
→ Our Lecturers
→ Course structure and modules
→ Working and studying
→ Admission and registration
→ FAQ